【内存分配与管理】malloc原理剖析
前言
当我们谈论程序性能时,总绕不开“内存”这个话题。内存管理如同程序的血脉系统,决定着程序的效率、稳定性和资源利用率。我们对内存的理解不能只停留在malloc/free、new/delete的简单调用层面,更要对其背后的机制以及设计缘由有所理解。
这是“内存分配与管理”系列的第一篇文章。我们将从最基础、也最重要的malloc开始,逐层揭开内存管理的神秘面纱。malloc不仅仅是C语言中的一个库函数,更是理解现代操作系统内存分配思想的窗口——它的设计哲学、实现策略、以及效率与通用性的权衡,构成了整个内存生态的基础。
在具体说malloc之前,我们先分清楚几个常见的概念:allocator、malloc和ptmalloc:malloc理解为分配内存的接口,allocator是一个负责内存分配和回收的具体策略实现。在Linux + glibc默认环境下,通过ptmalloc策略来实现(ptmalloc是一个名称);Google实现了tcmalloc策略,微软实现了mimalloc….
arena
ptmalloc针对堆管理,最顶层的管理结构为malloc_state,即arena
arena(分配器实例)
└── heap(一段连续内存区域)
└── chunk(用户分配单位)
struct malloc_state
{
// 本arena的锁
mutex_t mutex;
/* Flags (formerly in max_fast). */
int flags;
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
//当前arena中最高地址的、尚未分配的连续内存块
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
// small/large/unsorted bins
mchunkptr bins[NBINS * 2 - 2];
// Bitmap of bins
unsigned int binmap[BINMAPSIZE];
// 链表连接所有arena
struct malloc_state *next;
/* Linked list for free arenas. */
struct malloc_state *next_free;
// 本arena从系统分配的总内存
INTERNAL_SIZE_T system_mem;
INTERNAL_SIZE_T max_system_mem;
};
【arena是什么?】
每个线程都会绑定一个arena,其代表着一整套完整的malloc管理体系,独立着管理多个heap(非主arena的heap来自于多个mmap区域),这些heap通过链表相连,共用一套bins,而arena通过top指针指向当前正在被使用的heap
arena
├─ fastbins
├─ smallbins
├─ largebins
├─ unsorted bin
├─ top chunk
└─ mutex
【arena的类别有哪些?】
main arena:即对应到进程的初始堆,可通过brk/sbrk系统调用扩展堆大小,即来自进程对应的“堆”,每个进程有且只有一个main arena。
thread arena:即每个线程独有的arena(不超过数量限制的前提下),需要通过mmap单独映射内存以扩展heap,多个内存块是离散的
为什么不用brk给所有arena扩展?
brk只能线性增长,但是多线程情况下,需要多块独立的内存,可以分别独立扩展、独立释放。如果线程被回收了,则线程申请的内存同样需要被回收,而对于进程地址空间下的heap来说,其无法做到这一点,必须从top开始释放内存,而通过mmap映射的内存可以通过unmmap单独释放
多线程程序中可能有多个heap VMA是什么意思?不是所有线程共享同一个heap吗?
准确来说,多线程程序中可能存在“多个由mmap 创建的 heap-like VMA” 指的是,多线程中只能使用mmap作为动态内存的分配来源,这些mmap VMA位于虚拟地址空间中的文件和匿名映射区,其不属于进程的heap,但是在线程眼中被当作heap使用。此时,就会存在多个匿名mmap VMA,它们分别属于不同的arena,但是仍然属于同一个进程地址空间中。
一个多线程程序的内存分配情况可能如下所示:
[ text ]
[ data ]
[ brk heap ] ← main_arena
[ mmap arena 1 ] ← thread_arena1
[ mmap arena 2 ] ← thread_arena2
[ mmap arena 3 ]
[ stack thread1 ]
[ stack thread2 ]
线程1 (绑定主arena) 线程2 (绑定arena1) 线程3 (绑定arena2)
| | |
v v v
main_arena malloc_state1 malloc_state2
+-------------+ +-------------+ +-------------+
| mutex | | mutex | | mutex |
| fastbinsY[] | | fastbinsY[] | | fastbinsY[] |
| top ------------> [heap] | top ------------> heap1 | top ------------> heap2
| bins[] | +------+ | bins[] | +------+ | bins[] | +------+
| ... | | chunk| | ... | | chunk| | ... | | chunk|
| system_mem | | chunk| | system_mem | | chunk| | system_mem | | chunk|
+-------------+ | ... | +-------------+ | ... | +-------------+ | ... |
+------+ +------+ +------+
brk堆 mmap区域 mmap区域
我们知道了arena是什么,以及如何获取内存,那么arena是怎么和线程交互的?
如果线程第一次分配内存:
对于第一个分配内存的线程:使用main arena
对于其他线程:会遍历已有的arena,尝试找到一个未被其他线程使用的arena绑定(即锁是空闲状态),若所有arena都被占用,则会创建新的arena。arena默认数量上限为8*CPU核数,每个线程都会尝试绑定一个独有的arena,如果arena数量达到上限,则多个线程会共享同一个arena
如果线程后续需要分配内存:则优先复用先前使用过的arena,如果其已被其他线程占用,则去尝试使用其他的arena,而不是干等着。这是为了提高内存利用效率,防止明明一个进程分配到了大量内存资源,但线程依然无法获取
【为什么要有arena?其优点和缺点是什么?】
arena的主要设计目的是为了减少多线程下分配内存的锁竞争。 如果所有线程的malloc/free都需要依赖于同一个堆结构,那么每次分配/释放内存需要抢同一把锁,性能会非常低下。
其缺点在于,在多线程下每个线程都有自己的arena,A线程中的空闲块无法被B线程使用,可能导致明明分配给了该进程较多内存,但是依然不够用的情况,这就会导致内存膨胀,整体的内存利用率下降。
内存池内存管理机制
为什么堆要用内存池管理内存?而栈不需要?
从操作系统资源粒度来看:操作系统只提供了“页级别”的粗粒度管理,内核负责建立VMA、建立页表映射关系、分配物理页框,整个过程都是以页为基本单位的。但是用户程序却需要几十几十字节的内存,对于这种远小于4KB页大小的请求,如果没有allocator作为中间层负责页内细粒度的分配,那么会导致内部碎片严重、内存利用率极低。
从生命周期控制来看:堆内存的释放允许任意顺序,生命周期不可预测。如果没有allocator,无法记录哪些内存块是空闲/已用的。相比于栈,栈内存的分配是严格按照LIFO——后分配、先释放的,生命周期相互嵌套,出作用域后直接释放,不存在该问题
从碎片控制的角度来看:由于堆内存的分配在空间上不是连续的,这就会可能出现外部碎片问题,如果没有allocator,就无法合并、切割,否则很快就无法分配大块内存区域
从系统调用申请内存的角度来看:brk()/sbrk()/mmap()属于系统调用,如果每次申请内存都要调用这三个系统调用的其中之一,触发用户态到内核态的切换,是非常影响性能的。相比之下,栈的内存分配只需要通过移动栈指针即可
内存池具体管理方法
如何描述堆虚拟内存
隐式链表技术
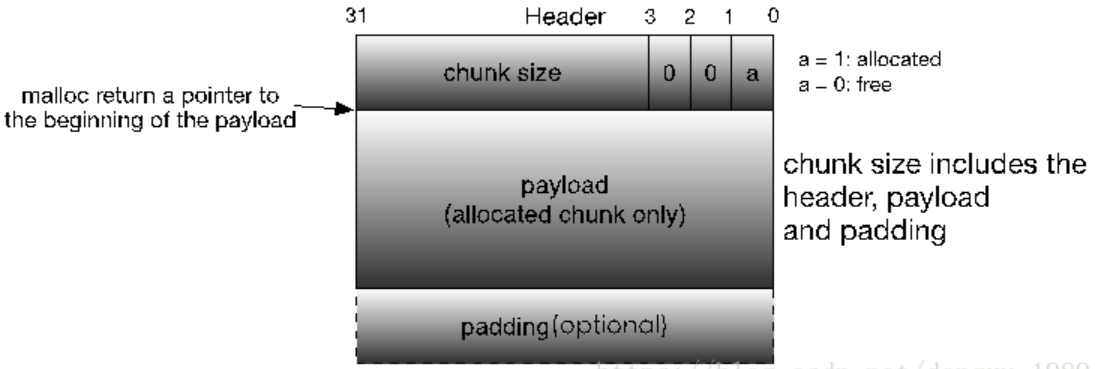
malloc将整个堆内存空间分为连续的、大小不一的chunk,chunk即为堆内存的最小管理单位。
为了区分不同的内存块的信息,比如已分配、未分配……会将这些信息直接嵌入到chunk内部
堆内存要求chunk的大小必须是8的整数倍,因此chunk size的后三位是无效的,为了充分利用内存,就将这三位作为chunk的标志位。
而padding部分则是用于内存对齐,让整个chunk为8的整数倍
allocated chunk:
free chunk:
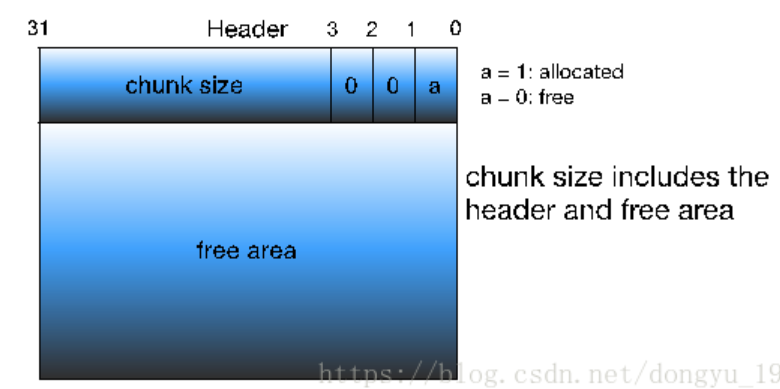
此时,整个堆内存组织为一个连续的,已分配或未分配的chunk序列
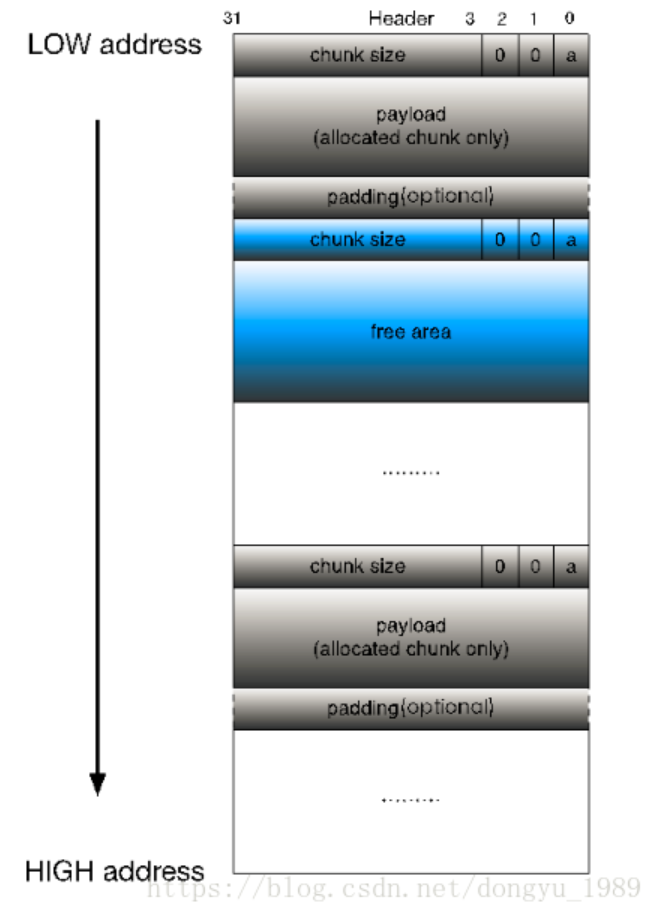
这种结构叫做隐式链表,我们只要拿到堆的起始地址,就可以根据每个chunk中存储的size信息,遍历所有chunk,以找到合适的chunk进行分配
缺点:遍历效率低,难以进行不同chunk之间的合并,久而久之,就会导致堆内存被分割为许多内存碎片。为什么不能合并?假设下面这样的场景,从上到下有3个内存块ABC,假设释放B内存:如果想和C合并,只需要让B内存的起始地址加上记录的chunk size即可得到C内存的起始地址,根据C的标志位即可判断是否可以合并;但是想和A合并较为困难,因为我们没有办法找到上一个内存块(高地址),无法判断,最坏情况下必须遍历整个堆才可以将AB合并
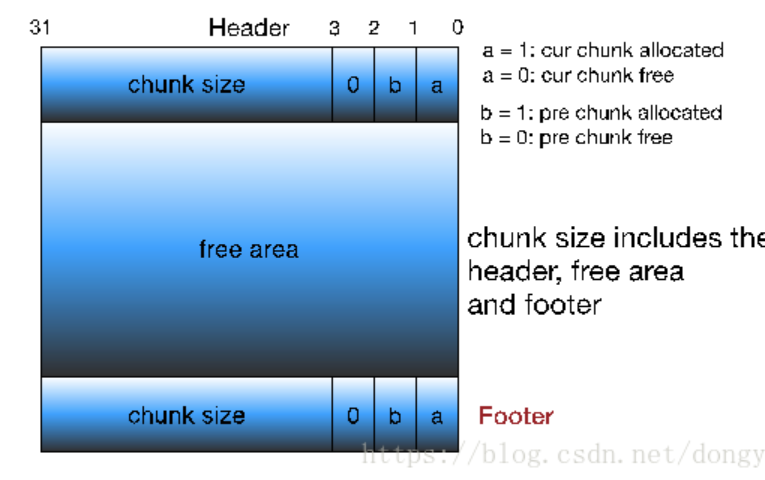
带边界标记的合并技术
Kunth在每个chunk的最后添加一个和header的副本——footer,此时,只要拿到了一个chunk的起始地址,将该地址+4就可以获得到高地址的chunk的信息了
问题:只有free chunk才需要footer,allocated chunk并不需要,此时footer对于allocated chunk是无用的
优化:用第1位,表示前一个chunk是allocated还是free。如果为1,则代表前一个chunk为allocated,当前chunk地址的前4个字节为前一个allocated chunk的payload或padding,此时,allocated chunk就算不保留footer也不会导致相邻的free chunk访问自身出错;如果为0,则代表前一个chunk为free,则将二者合并
free chunk:
支持多线程
随着技术的发展,堆内存管理器需要添加对堆多线程的支持,可是,此时chunk的标志位已经不够用了,我们还需要两个标志位——一个用于判断当前chunk是否属于主线程,另一个判断当前chunk是由mmap得来的还是由brk得到的。
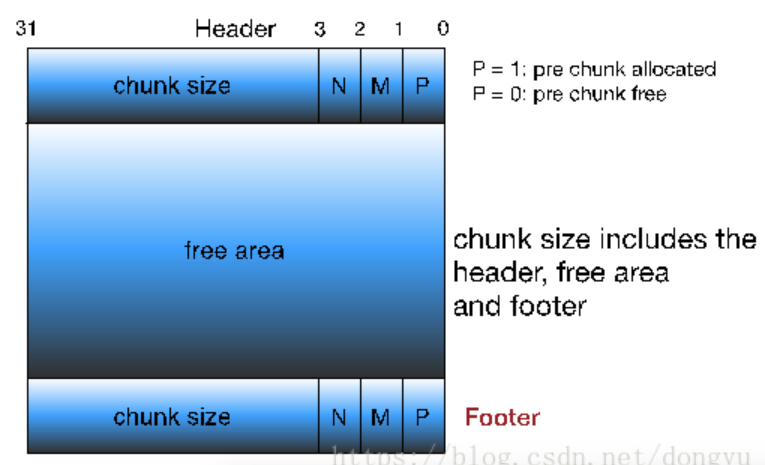
思考先前chunk的缺点:是否有必要在一个chunk中,同时保存前一个chunk的已分配/未分配标志位和当前chunk的已分配/未分配标志位?没必要,只保存前一个chunk的已分配/未分配标志位就够了,对于当前chunk是否已经分配,完全可以查下一个chunk的Header得到。此时满足要求。
第0位P(PREV_INUSE) 则代表前一个chunk是否已经被分配,如果为1则代表已分配,是一个allocated chunk,为0则代表未分配,是一个free chunk。
第1位M(IS_MAPPED),表示当前chunk对应的是哪个区域的虚拟内存,1表示文件和匿名映射区,0表示heap区
第2位N(NON_MAIN_ARENA),表示chunk是否是thread arena
此时的free chunk:
allocated chunk:
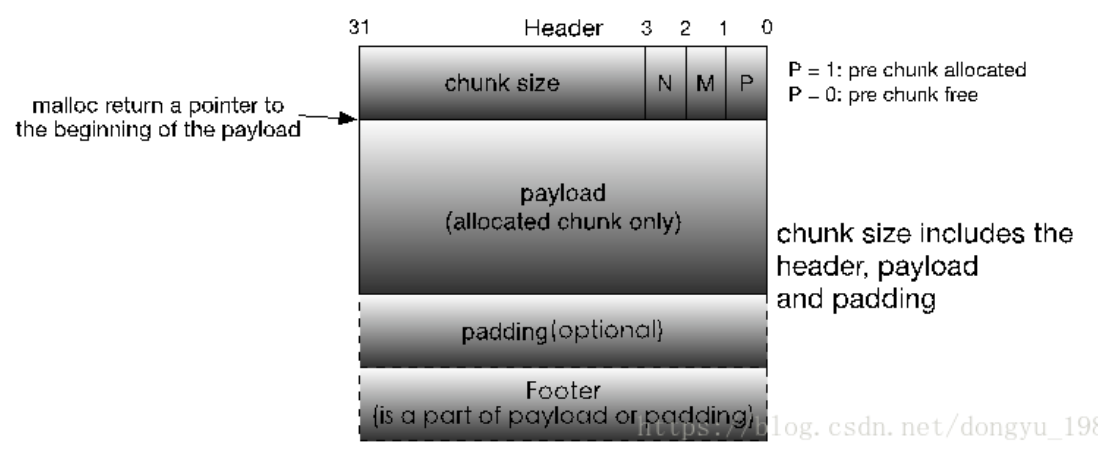
同理,发现对于不同的标志位,只需要存储一份即可。所以,将原先的footer中的标志位部分统一为prev_size,并挪动到chunk头部
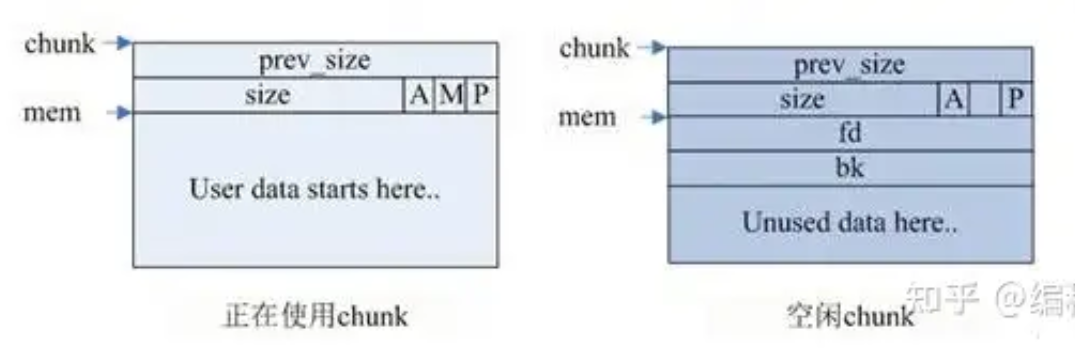
如何组织堆虚拟内存
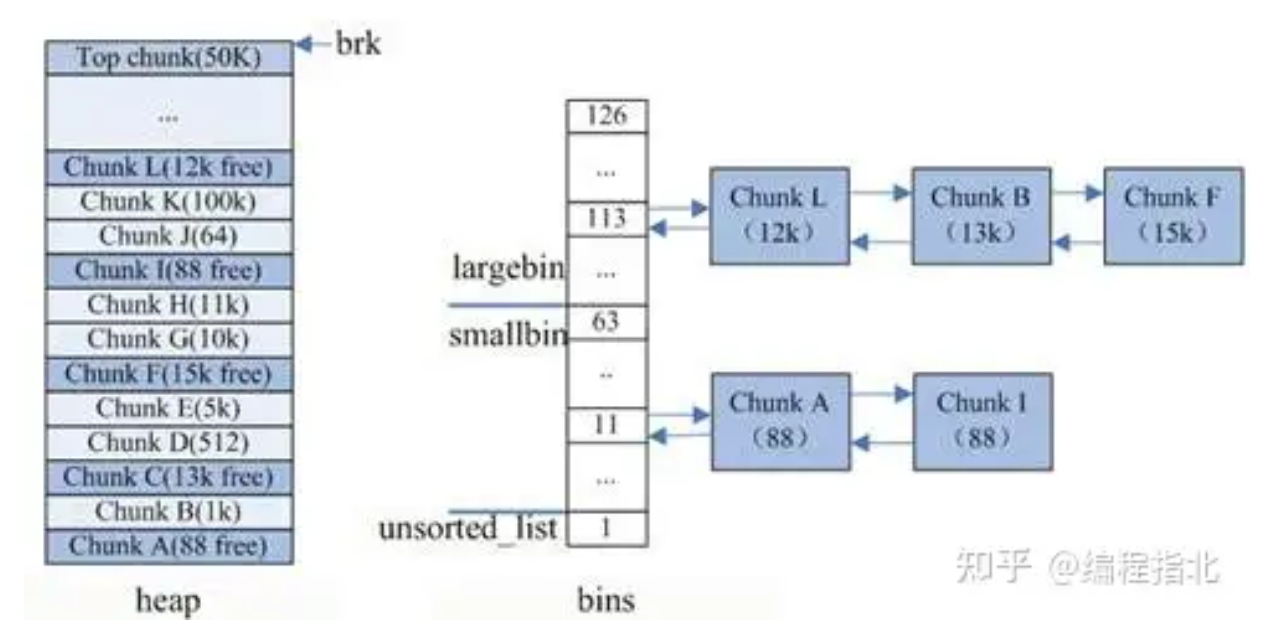
如果我们通过隐式链表的方式管理chunk,则总会涉及到chunk的遍历,效率极低,由此引入了半侵入式链表来提高堆内存的分配和释放效率。
bin中各个free chunk是如何连接在一起的? free chunk的frea area中会有两个指针,分别指向当前chunk所属链表中的前一个chunk和后一个chunk
链表中的节点即为free chunk,链表称之为bin;为了将这些bin管理起来,通过数组fast bins和bins来将所有bin的头结点存储起来,二者同属于malloc_state
struct malloc_state
{
……
/* Fastbins */
mfastbinptr fastbinsY[NFASTBINS];
……
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2]; // #define NBINS 128
……
};
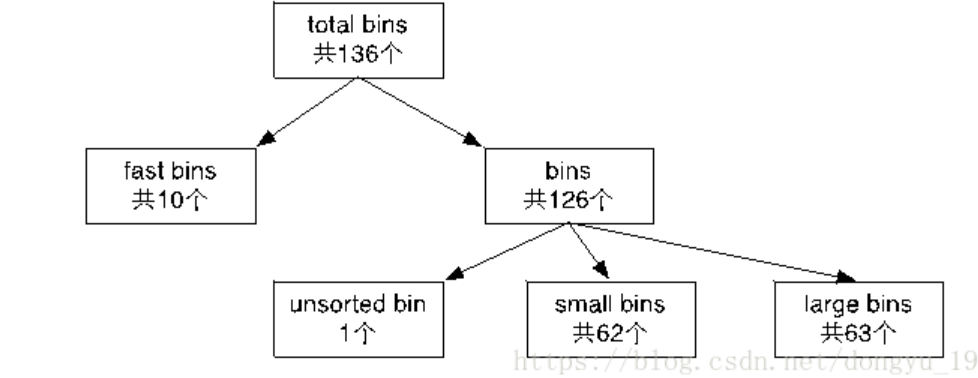
fast bins
(规定下文中,chunk size代表malloc_chunk的实际大小,chunk unused size为实际可用大小,前者比后者大16字节,用于存储prev_size,size以及两个指针)
作用:存放小尺寸且快速分配的空闲块
设计目的:快速地分配和释放小内存
程序中会经常申请和释放较小的内存空间。如果一释放就被分配器合并为一个较大的chunk,那么一旦又有小块内存的请求,那么分配器又需要把大的空闲内存做切分,无疑是比较低效的。所以,引入了较小块内存fast bin。
特点: 链表特点:每个fast bin都是单链表且总数为10,10个fast bin中所包含的fast chunk size是按照递增16字节排序的,比如第一个fast bin中所有的fast chunk size为16字节,第二个fast bin中所有的fast chunk size为32字节
为什么是单链表+LIFO?通过单链表就可以实现删除和添加操作。删除(malloc分配)即进行头删,添加(free释放)操作即头插,不需要对中间的节点进行操作,为O(1)操作。之所以要LIFO,是因为根据temporal locality原理,刚释放的chunk很可能马上再用,LIFO可以提高效率
节点特点:fast bin中的fast chunk大小较小,chunk unused不大于64字节,且所有的fast chunk不会自动合并,有延迟合并的特点。
合并只会发生在malloc请求large chunk、malloc请求smallbin但是smallbin为空、free 非 fastbin chunk或显示地调用malloc_consolidate(),此时会触发malloc_consolidate(),将所有的fastbin chunk取出并与相邻块合并,放入到unsorted bin中
此外,会将fast free chunk的prev标志位置为1,保证不会对fast free chunk进行合并操作,这是其设计目的决定的。
unsorted bin
作用:当一个chunk被释放时,它首先被放入unsorted bin,而不是直接放入其他bins。其是free后chunk的“缓冲区+热缓存层”,用于延迟分类并提高复用概率
设计目的:1.降低free成本。如果每次free内存,都立刻判断是smallbin还是largebin,larginbin还要维护有序结构,并加入到其中,效率较低。所以,会首先合并相邻chunk并先放进unsorted bin中
2.提高命中率。程序中有个重要现象——刚释放的内存,大概率会被马上申请,可以理解为访问的局部性原理。所以如果把这块内存又放到smallbin/largebin中,相比于将这些热数据放在一个unsorted bin中,其查找时间会更多
特点:只有一个unsorted bin,其为双向链表且不排序,FIFO——头插(释放内存),遍历时从尾部开始查,并优先尾删(malloc分配)
为什么是双向链表 + FIFO?因为遍历时可能删除中间节点,而单链表删除中间节点的成本高,为O(n),在知道要删除的节点的情况下,需要通过遍历获取前驱节点。FIFO的效果是,如果freeABC,则顺序为C–>B–>A,但是malloc检查是从尾部A开始检查的,目的是让最早被释放的内存优先被检查,防止某些块长期滞留
small bin
作用:用于管理比 fast bins 稍大一些的小尺寸空闲块,支持合并
链表本身特点:共62个small bin,为双向链表,FIFO——内存释放操作就将新的chunk头插,分配操作就尾删
节点特点:一个small bin中的所有free small chunk大小相等,第一个small bin的size为16字节,后续递增8
large bin
作用:用于管理超过 small bin 范围的大尺寸空闲块
链表本身特点:其大体逻辑和small bin类似,区别在于单一large bin中每个chunk的大小不是相同的,从链表头到链表尾部呈现递增趋势,采用范围管理策略,而不是small bin的固定大小管理策略
关于bins的初始化时机:
注意,bins不是“预分配内存”的缓存池,而是已经分配过、又被free的chunk回收站。在第一次malloc前,bins完全是空的,直至第一块内存区域被free,如果大小较小则放入fastbins,否则合并并放入到unsorted bin中,再分类放入到smallbin/largebin中
malloc流程梳理
1.void* p = malloc(size)。内部首先内存对齐(8/16字节),并加上chunk header大小,得到normalized size
2.tcache中查找。tcache为线程本地缓存,按照size class分桶,LIFO,O(1)查找且无锁。但是其容量较小,且只会缓存小对象,在高并发下依然无法替代arena,可能导致频繁的锁竞争
thread
└── tcache(每线程私有)
├── size class 1 → 链表
├── size class 2 → 链表
└── ...
3.选择arena并获取到其对应的锁,开始从bins中查找何时的chunk,此后的查找都是在持锁的状态下完成的
4.fastbin中查找。如果nb属于fastbin范围内(80字节左右),则做精准匹配,如果fastbin[index]非空,则返回,否则进入下一次
5.smallbin。如果nb属于smallbin范围内(小于512字节),则将nb转换为smallbins索引,做精准匹配,并从对应的smallbin中取出一个chunk并返回
index = size_to_smallbin(nb)
if smallbin[index] 非空
取一个 chunk
标记 inuse
返回
6.unsorted bin延迟分类层。做最接近匹配,遍历unsorted bin,在第一次满足nb>=chunk.size时,将该chunk从unsorted bin中移除,并将其做切割,将富裕部分根据其大小插入到smallbin/largebin中,并返回结果。注意,对于不符合大于等于条件的chunk都会被转移到smallbin或largebin中
如果遍历完unsorted bin依然没有找到合适块,即nb<所有chunk.size,此时unsorted也会被清空,因为已经被分类
for (chunk in unsorted):
if chunk.size >= nb:
从 unsorted 摘除
if chunk.size - nb >= MIN_CHUNK_SIZE:
切割
remainder 分类插入 smallbin/largebin
返回前半部分
else:
将该 chunk 分类到 smallbin 或 largebin
7.largebin。做最接近匹配,目标是找到>=nb的最小块,会先定位到index,得到largebins[index],再在其中找到目标快,如果有剩余则做切割,将剩余部分插入到smallbin或largebin中,并返回
8.top chunk。如果top.size()>=nb,则从top中做切割,将剩余部分插入到smallbin或largebin中,更新top指针,并返回
9.向系统申请内存以扩展堆。如果nb<128KB,则调用brk()扩展heap,更新top chunk并再次尝试分配;如果nb>=128KB,则调用mmap()创建匿名映射,返回mmap chunk
10.返回地址。此时,用户得到的是chunk+header_size,但是还没有物理页
可能存在的问题:
既然unsorted bin作为热缓存层,为什么是malloc查找顺序是fastbin->smallbin,而不是先查unsorted bin?
因为smallbin是精确匹配层,如果请求在smallbin的范围内,直接通过O(1)时间复杂度即可确定是否存在可用的内存块:
smallbin[index] 非空 → 直接返回
相比之下,unsorted bin里chunk大小杂乱,查找unsorted bin的代价是O(n),且查找到后可能需要进行分割。
malloc分配内存的设计原则是,先查找“确定性精确命中”的结构,再查找“需要遍历判断”的较低效结构
是否所有的内存块在分配时,都需要切割?
不是。如果想要让smallbin命中,必须要请求大小和small chunk大小完全相同,即必须做完全匹配而不是最恰当匹配,由此来避免低效的查找。这是空间利用率与速度的折中。
如果unsorted bin或者large bin命中,则需要进行切割
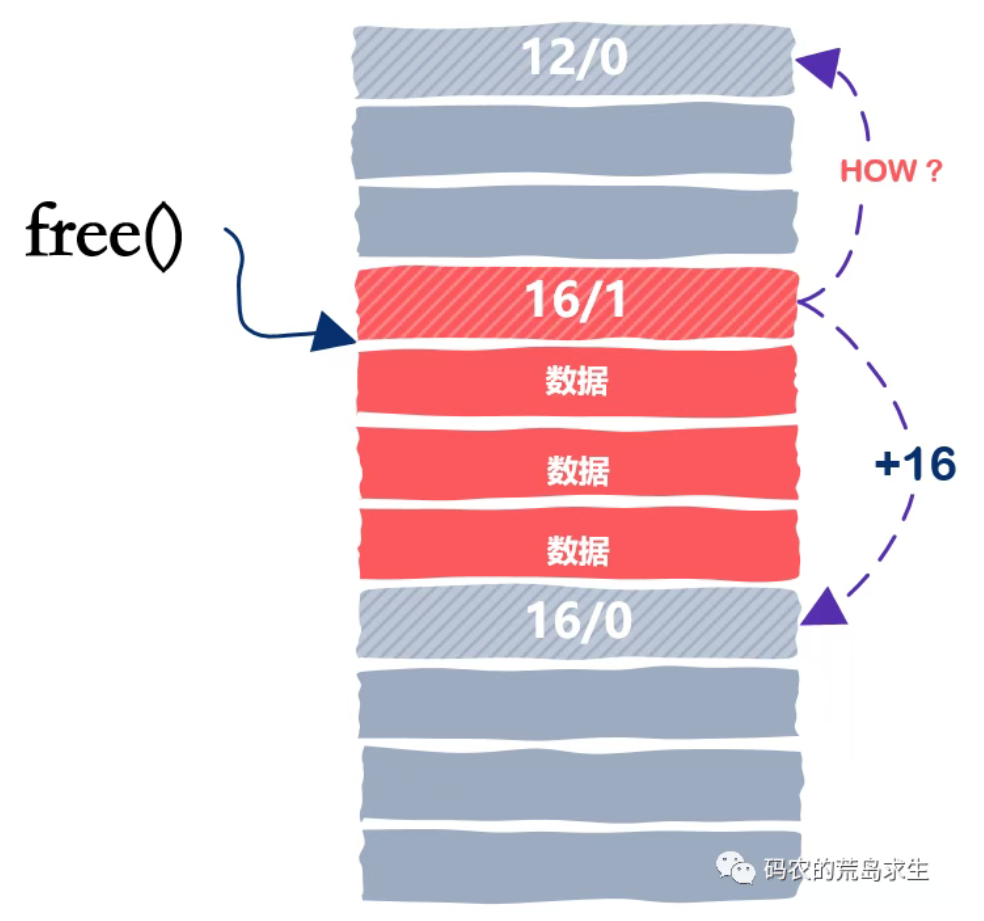
free流程梳理
1.定位chunk。free(ptr)将根据ptr定位到chunk的Header地址,获取PREV_INUSE、IS_MAPPED和NON_MAIN_ARENA信息
2.检查是否是mmap分配的chunk。通过查看IS_MAPPED标志位,可以判断是否是mmap分配的——如果是,则通过munmap(chunk,size)将虚拟地址区间移除、VMA移除、页表项删除并立刻释放物理页,归还给操作系统,不涉及任何合并以及bin;如果不是,则进行_int_free()函数来合并释放
3.检查是否属于fastbin大小范围。如果size <= 64B/128B,则将其头插到fastbin的单链表中,不做合并(延迟合并,因为小块频繁分配释放,很可能马上又malloc,合并的成本太高了),不清除PREV_INUSE
4.说明属于smallbin或是largebin的大小范围,进行合并。合并目标是,尽可能地让当前chunk和前一个chunk、后一个chunk合并。对于前一个chunk——通过Header中的PREV_INUSE标志位来判断前一个chunk是否为free,如果是free则通过chunk - prev_size来获取到前一个chunk的起始地址并合并;对于后一个chunk——通过chunk + size获取到下一个chunk的Header,检查其是否被使用,如果未被使用,则进行合并。合并的流程——从对应的bin中unlink(nextChunk),并让当前chunk->size += nextChunk->size
5.合并完成,将合并后的块放入到unsorted bin中。此时,虚拟地址依然存在、VMA存在、物理页也依然存在,并没有归还给操作系统,allocator认为可重用
6.特殊情况:合并到了top chunk。如果释放的块后面是top chunk,即chunk + size == top,则直接扩展top,不进入unsorted bin。此时,如果top_size > trim_threshold(一般是128KB),就会调用systrim,进而调用brk(new_end),让heap缩小,缩减mm_struct映射的堆区域与对应的vm_area_struct映射的虚拟地址范围,清除对应的页表项,并真正释放物理页,将物理内存归还给操作系统
重新理解free:
从进程的视角来看: free是“进程管理内存资源的行为”,等同于将这块内存的使用权还给了allocator,但是这块内存是否会交还给操作系统,取决于分配器策略,并不是free的必然结果
从数据结构的视角来看: allocator维护bins以及chunk状态,free本质上是对这些数据结构的操作,会根据ptr找到chunk并标记为free、尝试进行合并操作并插入到bin中,本质上是对堆管理数据结构的操作
从虚拟内存的视角来看: 对于小块内存(brk()),free不等同于删除虚拟页,VMA、页表依然存在且有效、PTE访问权限没有变化,此时并不是硬件层面禁止访问,只是属于未定义行为。比如,下面的代码通常不会立刻报错
free(p);
*p = 1;
对于大块内存,才会删除vm_area_struct、将物理页归还给操作系统,此时访问是硬件层面的错误
从内核视角来看: 绝大多数free并不会立刻进入内核,因为内存块已经交给allocator管理。只有在munmap、brk收缩和进程退出时才会进入内核态,调整映射,真正把物理内存收回
从硬件的视角来看: CPU完全不知道,CPU只做虚拟地址到物理地址的映射,free不会修改CR3、不会刷新TLB、不会改变PTE也不会触发page fault,除非munmap
究竟什么情况下才会真正将物理内存归还给操作系统?
一是mmap映射的区域直接通过munmap()归还,二是brk()调整收缩堆大小,内核才会调整虚拟映射、归还物理内存,此时的物理内存才可被其他进程使用
注意,释放内存必须从高地址,即heap的尾部开始释放。 例如下图中,只有最右边free区域可以被归还,中间的free块永远无法被归还
| allocated | free | allocated | free(top) |
不能归还中间部分的虚拟地址,这是由VMA机制决定的。 mm_struct通过heap_start和brk指针分别指向堆底和堆顶,vm_area_struct同样也会用start和end指针指向开始和结束地址。二者都说明了,这块虚拟内存区域是连续的。如果强行删除,会导致VMA被拆成两段,二者的语义被破坏,glibc的连续heap模型崩溃。所以,brk机制天然不支持中间部分裁剪
内存碎片
内存碎片是在什么情况下产生的?
第一层:allocator层碎片
外部碎片(空间总量够 但不连续)——malloc产生大小不同的chunk,切割时会产生剩余碎片;fastbin延迟合并,以性能换空间
内部碎片——chunk对齐导致
第二层:虚拟内存层
外部碎片:brk heap中的不可裁剪空洞,由于heap只能是单一连续的VMA 只可以尾部shrink,中间free无法通过brk归还
第三层:物理内存层
外部碎片:缺页中断触发物理页的分配,但是一张张4KB的页被打散分配给了不同的进程使用,如果此时某个进程需要2MB的连续页,可能难以分配,需要swap out
内存碎片如何处理?何时处理?由谁处理?
对于虚拟地址碎片:
heap空洞:中间的free chunk的虚拟地址仍然要保留,在一定时间内不能归还。其由ptmalloc来管理,这部分碎片的处理方式,需要等待未来被malloc复用——要不就是best-fit减少碎片,要不就是与相邻区间合并
总结一下,对于虚拟地址碎片,ptmalloc都有哪些处理手段——free时对smallchunk/largechunk立即合并、fastbin的延迟合并、unsortedbin的优先复用以避免频繁分割、trim的尾部处理;malloc时的best-fit策略,“尽可能保留大块内存,尽可能减小切割剩余大小”
对于物理内存碎片:
虽然虚拟地址不能被回收,但是物理页是可以回收的。
1.正常情况下,free后虚拟地址未被回收,页表映射关系依然存在,但是如果长期不访问,则在内存紧张的情况下会被swap out
2.现代glibc在一些条件下会主动madvise。此时,虚拟地址仍然存在,页表也依然存在,不过物理页被回收
说完何时回收,下面说说如何合并,减少物理内存碎片:Linux下buddy system对物理页进行管理,在物理页已经被回收,完全脱离进程映射后,buddy system可以合并相邻的free页以减少物理碎片
为什么allocator不频繁归还内存?
设计目标是——优先重用,减少无效、昂贵的系统调用。 一块刚被使用使用过的内存,很大可能会在不久后被再次使用。而如果free时直接把物理内存归还,就意味着需要再次调用brk()/mmap()系统调用、建立页表映射,代价太大
这也解释了为什么free后RSS(Resident Set Size 常驻内存集)可能不下降:RSS代表当前进程在物理内存(RAM)中实际占用了多少物理页,时操作系统视角下进程的真实消耗的物理内存量
一是释放内存块并不属于通过mmap映射分配到的大内存块,而是brk()分配的
二是释放的内存块并不在堆顶
三是,就算是堆顶的内存块,堆的大小小于trim_threshold(一般是128KB),glibc就不会调用systrim()来执行brk系统调用收缩堆。
这三种情况下,在操作系统看来这些内存块依然被进程占用着
总结
ptmalloc是glibc默认的内存分配器,通过arena机制降低多线程下的锁竞争,每个线程独立管理堆内存。它以chunk为最小单位,采用fastbin、smallbin、unsorted bin、large bin多级缓存策略,兼顾分配效率和碎片控制。free通常只将内存归还给分配器而非操作系统,只有大块mmap内存或堆顶收缩时才会真正释放物理页,这种设计以空间换时间,优先重用避免频繁系统调用。本篇文章主要梳理了malloc的流程,下一篇则主要聚焦于“为什么”的角度,梳理malloc为什么要这样做。在接下来的系列文章中,我们将以malloc为起点,逐步构建完整的内存管理知识体系。