【内存分配与管理】Unity内存分配
本文作为Unity内存管理系列的开篇,将聚焦于Unity的内存分配原理,深入剖析Boehm GC在托管内存分配中的具体实现,包括小对象与大对象的分配策略、空闲链表与内存池的设计、以及这些机制背后的性能考量。后续文章将进一步讲解Unity GC的回收机制与优化实践。
整体认识
Unity具有两套内存——托管内存Managed Memory和原生内存Native Memory。
Managed Memory即C#层的堆内存,其中存储了C#代码分配的对象,即class实例对象、string、装箱等,由C#运行时(Mono/iL2CPP)管理
Native Memory即Unity底层的C++层的堆内存,其中存储了Unity引擎内部的资源,比如纹理,模型,音频以及GameObject本体等,需要我们手动进行资源的卸载以及引擎内部的生命周期管理
┌─────────────────────────────────────────────────────────────┐
│ Operating System │
│ (物理内存 RAM) │
└───────────────────────┬─────────────────────────────────────┘
│
┌───────────────┴───────────────┐
↓ ↓
┌──────────────────────┐ ┌──────────────────────┐
│ Managed Memory │ │ Native Memory │
│ (C# Heap) │ │ (C++ Heap) │
├──────────────────────┤ ├──────────────────────┤
│ │ │ │
│ ┌────────────────┐ │ │ ┌────────────────┐ │
│ │ C# Objects │ │ │ │ Unity Engine │ │
│ │ - List<T> │ │ │ │ - GameObject │ │
│ │ - Dictionary │ │ │ │ - Transform │ │
│ │ - Custom Class │ │ │ │ - Renderer │ │
│ │ - String │ │ │ └────────────────┘ │
│ └────────────────┘ │ │ │
│ │ │ ┌────────────────┐ │
│ ┌────────────────┐ │ │ │ Assets │ │
│ │ MonoBehaviour │◄┼────┼─►│ - Texture │ │
│ │ (C# Wrapper) │ │ │ │ - Mesh │ │
│ └────────────────┘ │ │ │ - AudioClip │ │
│ │ │ │ - Material │ │
│ GC 管理: │ │ │ - AssetBundle │ │
│ - Incremental GC │ │ └────────────────┘ │
│ - Boehm GC │ │ │
│ (Mono/IL2CPP) │ │ 手动管理: │
│ │ │ - Destroy() │
└──────────────────────┘ │ - Unload() │
│ - DestroyImmediate()│
└──────────────────────┘
↑ ↑
│ │
C# 代码可见 部分可见
(Profiler: Mono 内存) (Profiler: Unity 内存)
【托管内存和原生内存之间如何交互?】托管内存和原生内存之间并不是完全隔离的,二者需要经常交互。比如我们通过C#代码访问Unity资源或者通过Unity API调用时,既会在原生内存上创建一个Unity Object,代表场景中真正的GameObject对象或是Component(Transform、Rigidbody等),也会在托管内存上创建一个“包装器”对象(比如GameObject对象),其中包含了一个指向Unity Object的指针,作为我们访问Unity Object的”句柄“
GameObject go = new GameObject();
这带来了一个重要的现象:假null问题。尽管Destroy了,但是托管内存上的C#对象还在,可是C++层对象已经被销毁了,如果只是通过C#的==来判断对象是否为空,会得到误导性的结果。
为此,Unity重载了==运算符,如果原生内存上的对象已经销毁了,那么就返回null,尽管C#层对象还没被回收
Destroy(go); if (go == null) { ... } // true
内存分配管理
Unity中使用C#创建托管对象时,这一步最终会通过调用到底层的GC内存分配器来申请原始内存,而这一步是在C/C++层完成的,随后运行时会在这块内村上构造托管对象,比如调用构造函数,写入对象头等。
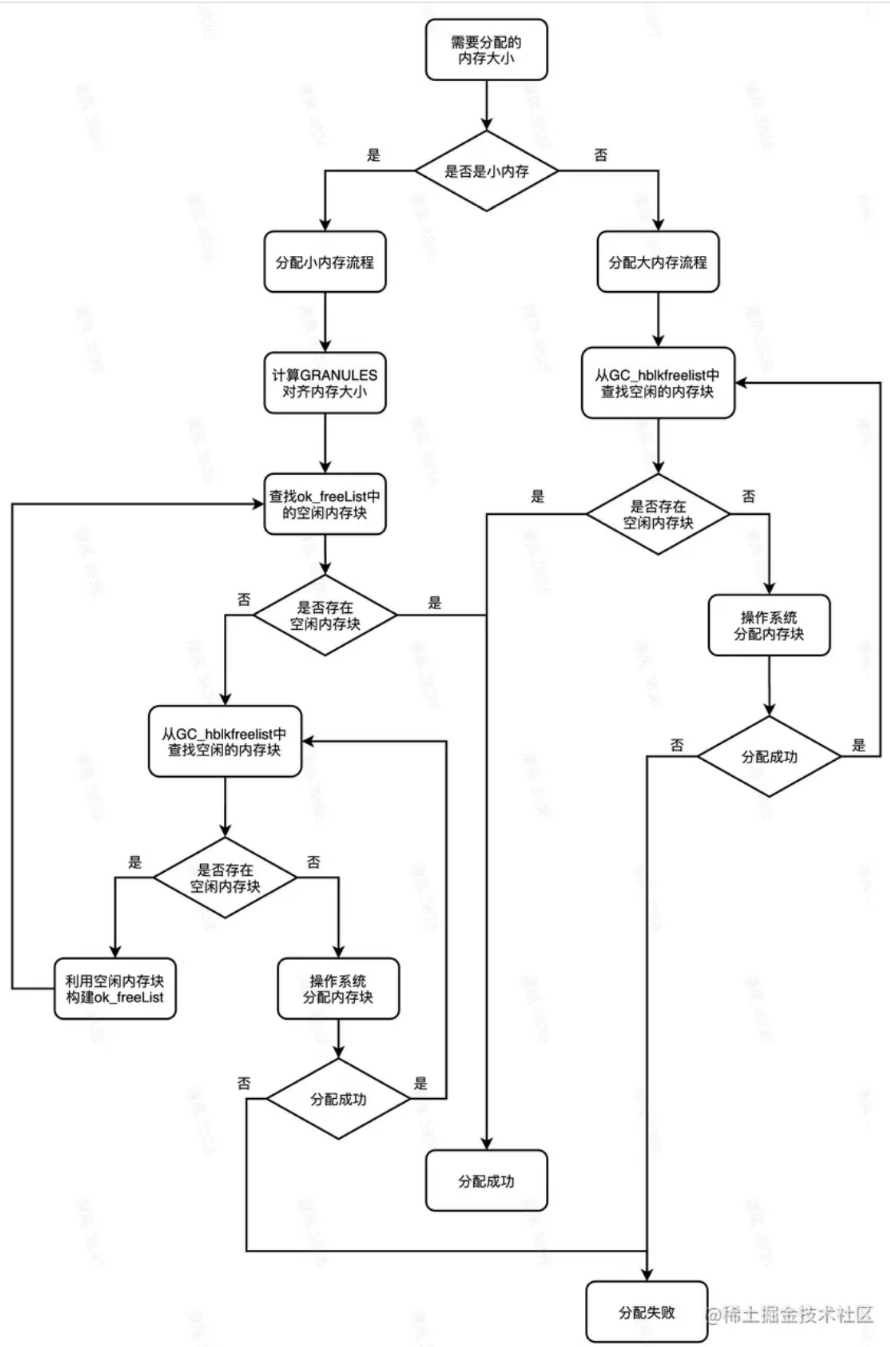
其大体思路和STL allocator类似,对于2048字节以内小对象,则通过free-list+memory-pool的方式分配;对于2048字节以上的大对象,则直接从memory-pool中分配内存
小对象内存分配
关键数据结构:
内存块 hblk(heap block):即实际存储数据的内存块,其大小为4KB,即一个page的大小。
struct hblk { char hb_body[HBLKSIZE]; //HBLKSIZE=4096 };一个hblk会被等大分割并插入到 ok_freelist 中,而内存块是直接从 ok_freelist中获得的,所以hblk中实际上会存放很多个”等大对象“。比如:
hblk (4KB) ├── obj (32B) ├── obj (32B) ├── obj (32B) ...header信息 hblkhdr:hblkhdr用于存储hblk的信息,对于存储小对象的hblk来说,每个hblk都有唯一的hblkhdr;对于大对象来说,即一个大对象对应多个hblk的情况下,只有大对象的第一个hblk才有hblkhdr,但是借助_top_index实现地址->hblkhdr的映射,从而找到hblkhdr。hblkhdr其以某种hash算法存在于全局存放堆信息的数组-链表结构_top_index中,GC能够正常运行依赖于该header信息。
如果是小对象,hb_sz记录了对应的hblk中每个小对象的大小,该hblk中存储的小对象数量可以通过 4KB/hb_sz得出。hb_marks标记出当前hblk中的对象的引用情况——0代表没有被引用,1代表被引用。比如,hblk为8KB,hb_sz为32B,那么对象数量为256,则hb_marks就需要256个bit,第i位对应第i个对象,标记其被引用情况。
如果是大对象,则hb_sz记录了当前hblk所属的大对象的大小,且hb_marks[0]代表了该对象是否被引用。该对象占用的hblk数量可以通过hb_sz / 4KB得出//头部信息 struct hblkhdr { struct hblk * hb_next; //指向下一个hblk struct hblk * hb_prev; //指向上一个hblk struct hblk * hb_block; //对应的hblk unsigned char hb_obj_kind; //kink类型 unsigned char hb_flags; //标记位 word hb_sz; word hb_descr; size_t hb_n_marks;//标记位个数,用于GC word hb_marks[MARK_BITS_SZ]; //标记为,用于GC }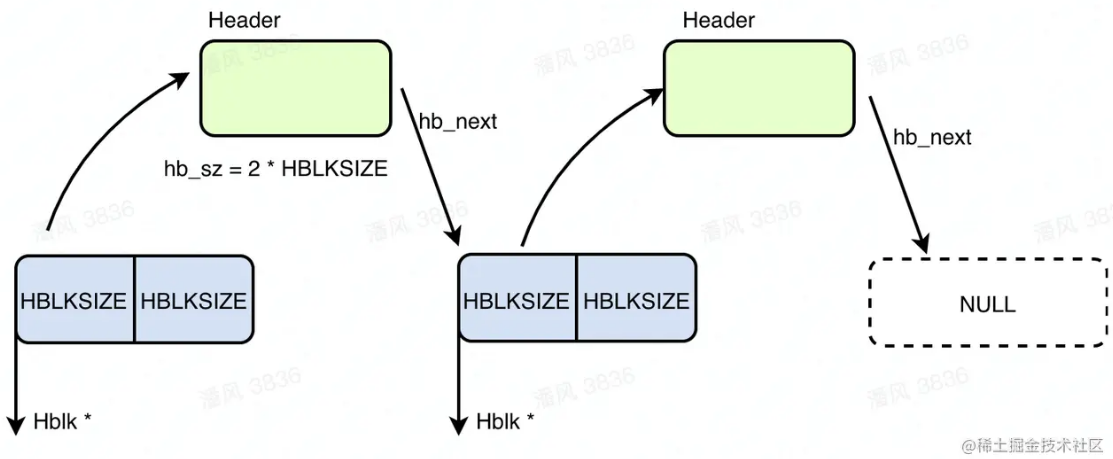
GC_obj_kinds[3]:在分配内存时,将要分配的object分为三种内存类型——PTRFREE、NORMAL和UNCOLLECTABLE。PTRFREE指的是,内部不包含指针的类型,扫描时可以直接跳过;NORMAL是内部可能包含指针类型,需要扫描;UNCOLLECTABLE则是无法被回收的内存,在垃圾回收时会作为根,比如静态变量和GCHanlde都属于UNCOLLECTABLE对象
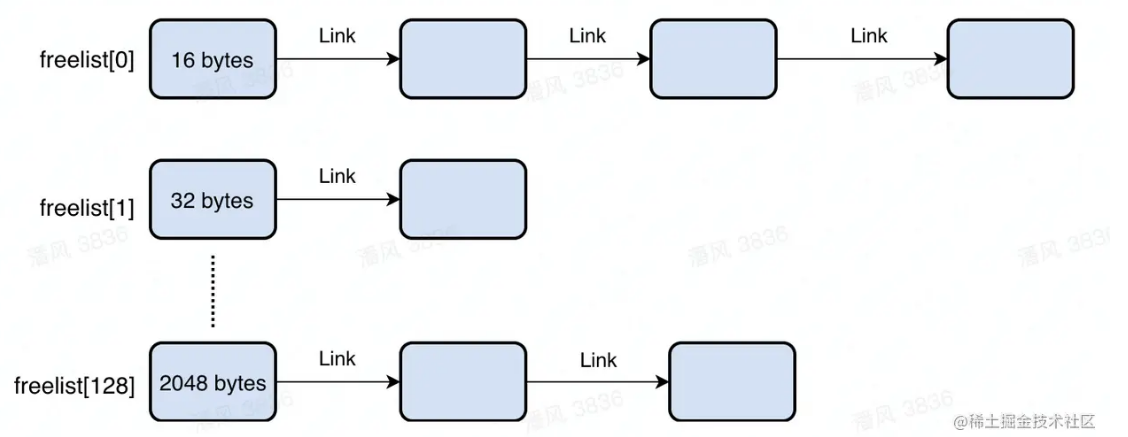
struct obj_kind { void **ok_freelist; struct hblk **ok_reclaim_list; ... } GC_obj_kinds[3];空闲链表 ok_freeList:ok_freeList是一个二级指针链表,对应维护了128个存储空闲内存块的链表,每条链表记录的内存块大小相同,不同链表内的内存块大小不同,相互间隔16字节。每一条链表中的空闲内存块是通过hblk等分填充的,每个空闲内存块中都包含了下一个空闲块的地址(小块只有在空闲时才会在内部存储下一个空闲小块的地址, 返回给用户时就是纯数据块了)
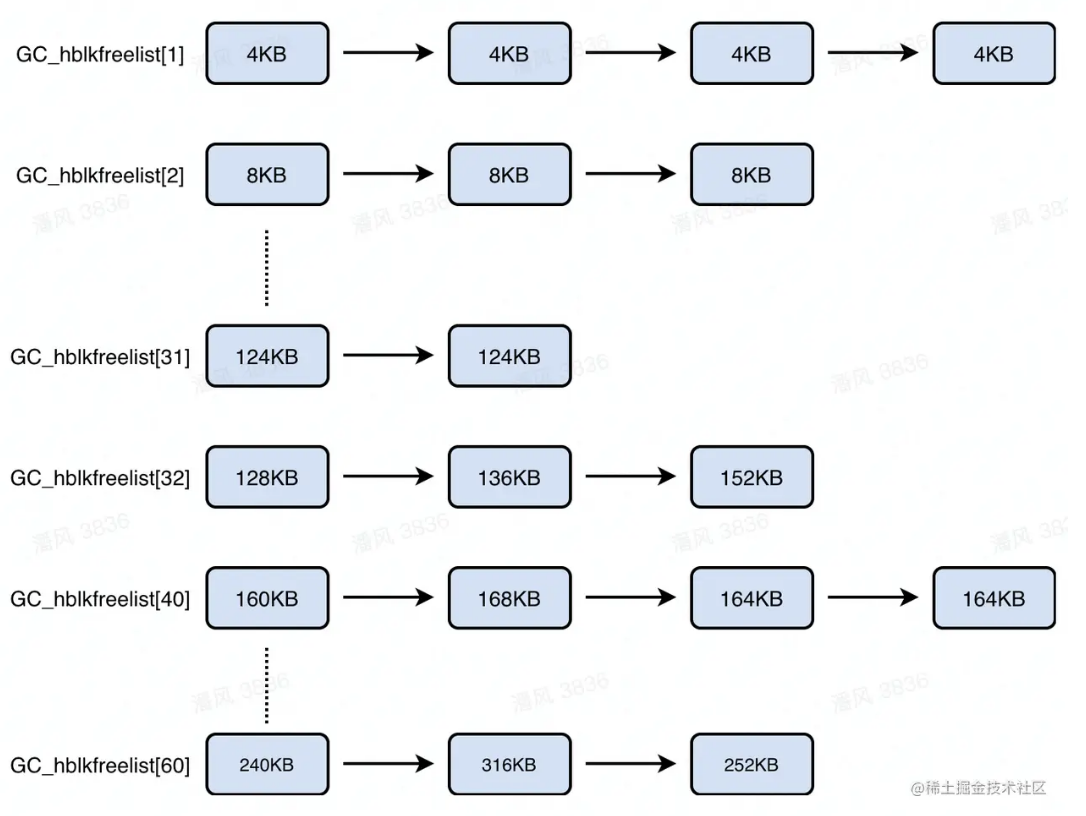
内存池空闲内存块链表 GC_hblkfreelist:类似于上面的 ok_freelist,但是在细节上有所不同。首先,在存储结构上,其是一个存储hblk地址的数组,hblk之间并不直接相连,而是通过hblkhdr间接地在逻辑上相连。遍历一条“链表”时,需要通过hblk的地址,查找到hblkhdr,再通过hblkhdr中的next指针找到当前“链表”的下一个hblk
hblk* p = GC_hblkfreelist[i]; while (p) { hblkhdr* hdr = HDR(p); // 通过地址查 header p = hdr->hb_next; // 拿到下一个 hblk }其次在大小上,每个内存块都以4KB为基本单位(而不是16B了),且从GC_hblkfreelist[32]开始,每个GC_hblkfreelist中存储的内存块大小不等,会有8种大小类型。例如GC_hblkfreelist[32]存储的内存块大小范围是128KB~156KB。
内存块分配获取流程:
根据目标内存块大小,首先对齐到16字节大小(但是如果刚好能被16整除,则再追加16字节)尝试从ok_freelist中获取到空闲的内存块——如果其中有空闲的内存块,则直接返回,流程结束;如果没有空闲的内存块,则调用尝试从底层的内存池的 GC_hblkfreelist 中获取内存块并填充ok_freelist(类似于allocator的refill())
如果GC_hblkfreelist中压根不存在可以被利用的内存块(为空或者太小):则根据通过对应平台下分配内存的接口(比如malloc)来分配内存,或触发GC。有多余的内存后,将内存块加入到相应的GC_hblkfreelist中,并将其header信息初始化,加入到全局存放堆信息的数组中
如果GC_hblkfreelist中存在可被利用的内存块,则调用GC_allochblk():根据所需字节数,对齐到4KB大小,以批量填充 ok_freelist,并根据该大小,计算出需要定位到哪一条GC_hblkfreelist中查找合适大小的内存块。如果经过查找,该GC_hblkfreelist中不存在合适的内存块,则从包含更大内存块的GC_hblkfreelist中寻找内存块具体的查找流程GC_allochblk_nth():
如果遇到了恰好符合要求的内存块大小,则直接return,填充ok_freeList。如图,假设从GC_hblkfreelist中获取到了一个4KB的内存块,且先前的目标是填充16字节的ok_freelist,则将4096字节按照16字节分割并进行填充
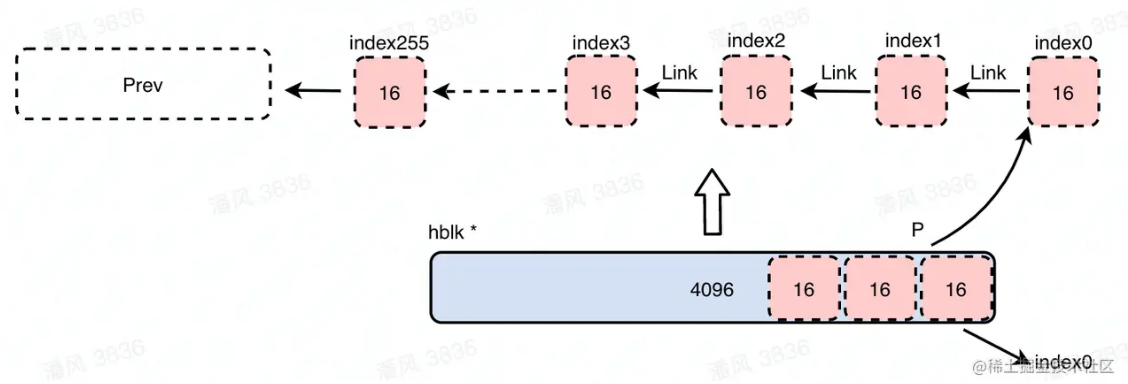
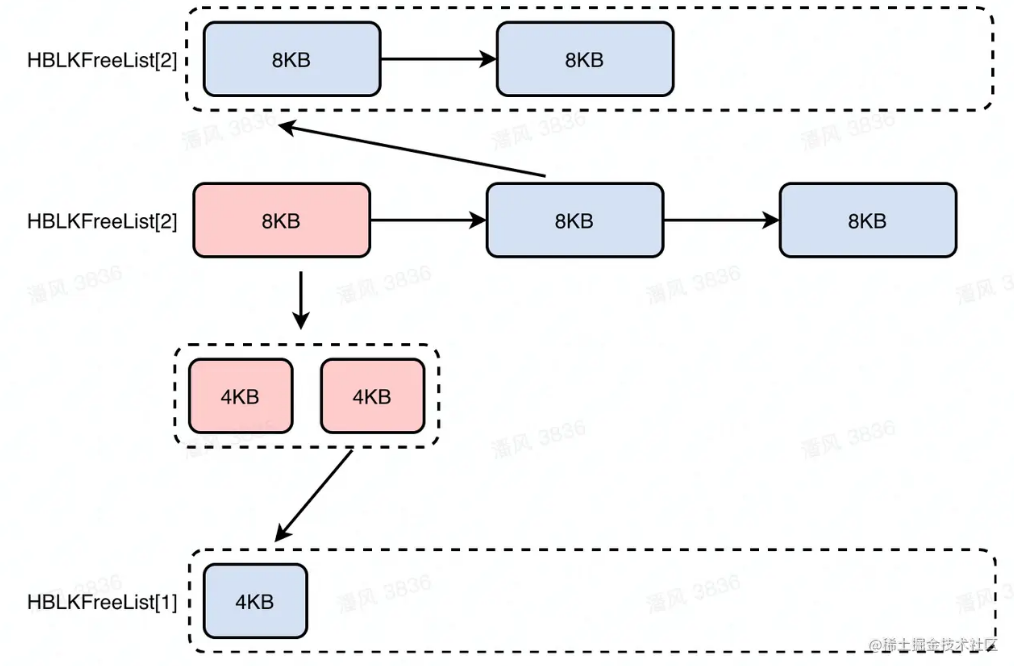
如果没有可以精准匹配的内存块,但是遇到了一个稍大的内存块,则将其分割并返回较为精确的一部分并填充ok_freeList,同时将剩余部分重新挂回到GC_hblkfreelist中,修改被分割的内存块的header信息。比如该图中,目标是要4KB大小的内存块,但是只有8KB的了,所以会将8KB大小的内存块分割
【设计原理思考】
为什么对于小对象,需要通过ok_freelist来管理,而对于大对象则不需要,直接从GC_hblkfreelist取内存块?
实际上,STL allocator、tcmalloc和jemalloc使用的都是这套策略
小对象的内存分配属于热路径,需要让多个对象共享一个hblk,在hblk内部做更细粒度的”对象级“复用,减少小对象带来的内存碎片问题(主要是内部),同时可以提高小对象的分配效率,做热路径优化(程序中大部分的内存分配需求都是小对象,而ok_freelist中获取为O(1),其严格按照size class划分,但在GC_hblkfreelist中就不是O(1)了)
大对象的数量较少,一般都是可以直接对应一个或多个hblk,可以直接使用GC_hblkfreelist按照hblk做”内存块级别的“管理”,避免不必要的复杂度。对于大对象来说,主要需要解决的问题是外部碎片
进一步的,之所以一个hblk为4KB,是因为其与page的大小相同,可以提高内存分配效率(mmap/brk都是按照page扩充的),减少TLB miss
为什么将内存块和其头部信息分开存储,即分为了hblk和hblkhdr?
将hblk和hblkhdr分离后,Boehm GC通过二级索引结构_top_index->bottom_index->header,可以通过地址分段进行索引,支持在O(1)内查找到header。其好处在于:
在Mark阶段快速判断是否为“指针”:Mark阶段可以利用地址和hblkhdr的映射关系,快速检查是否是一个指向对象的指针
局部缓存性好:GC经常只需要header信息,比如Reclaim阶段并不关心具体数据,只关心哪些数据没有被标记,所以完全不需要访问对象本身。此时,如果header散布在各个hblk前,cache miss严重。而将header集中存储,比如前面提到的bottomeIndex一维双向侵入式链表,其效率更高
避免了元数据对纯用户数据的干扰
Boehm GC中用到了很多链表结构,不会因为cache miss较多而导致效率低下吗?
ok_freelist为二级链表,但实际上每一条链表中填充的内存块都是连续的,因为它们都是通过同一块hblk等量分割形成的。 并且,在实际分配过程中,并不会真的遍历ok_freelist,都是直接通过O(1)定位到指定大小的链表并从头部获取内存块。
GC_hblkfreelist为指针数组,GC_hblkfreelist[i]代表了hblk的地址,尽管是数组,但是其效率一定低于ok_freelist,因为GC_hblkfreelist[i]的物理结构类似于:
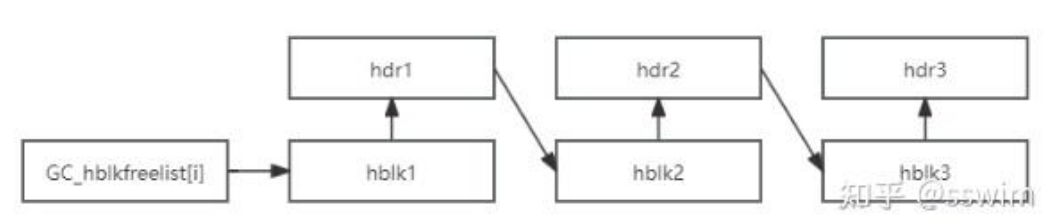
hblk之间并不直接相连,而是通过hblkhdr间接地在“逻辑上”相连,遍历一条“链表”时,需要通过hblk的地址,查找到hblkhdr,再通过hblkhdr中的next指针找到当前“链表”的下一个hblk,cache miss严重
此外,辅助_top_index的也是一个一维的bottom_index双向侵入式链表,其存储了指向hblkhdr的指针数组

之所以这样做,一是有约束难以转化为使用数组,二是高频低频路径。
具体来说,每个hblk都是稀疏且不连续的,这一点是无法改变的,是由heap的特点决定的,强行数组化反而麻烦且浪费空间,链表更适合管理非连续内存、支持块合并,这些特性对于GC的内存管理比cache命中率更重要
此外,真正的高频访问路径在ok_freelist上,需要从中获取内存块以创建对象,而遍历这些链表大部分发生在无空闲内存块和GC触发等低频路径上,对性能影响有限。比如ok_freelist中没有可用的内存块时,则会到GC_hblkfreelist中查找,reclaim时需要根据所有的hblkhdr中的引用信息来判断回收哪个对象,都并不属于高频路径。
【实践启发】
缓存数据的开辟。有时会使用字节数组byte[4096]用做缓存,实则反而导致内部碎片严重,需要多分配一个hblk,正确的方法是将长度设置为4096 - 32 - 1 = 4063。-32是因为在IL2CPP下,数组需要32字节的额外内存来存储信息,而-1是因为从ok_freelist获取内存块时,如果是16的整数倍,则会再向上对齐一次。
GC时机的控制。在进度条加载时,申请一次强制的内存清理;在比赛过程中,将GC改为手动,以防止比赛过程中有明显的卡顿,这么做的前提是,内存优化较好
大对象内存分配
大对象内存分配时,是直接从memory-pool中获取内存块,即直接从GC_hblkfreelist中获取内存块,不再走ok_freelist,其逻辑和GC_allochblk()一模一样
总结
本文详细拆解了Unity托管内存的分配机制,从整体架构出发,逐步深入到Boehm GC的核心数据结构与分配流程。我们可以看到,Unity的内存分配器在设计上与C++标准库的allocator乃至tcmalloc、jemalloc等高性能分配器有着相似的思路:通过分级管理、空闲链表、内存池等手段,在分配效率和内存利用率之间取得平衡。
理解这些底层原理,不仅能帮助我们写出更高效的Unity代码,更能为后续深入学习Unity GC的回收机制与优化策略打下坚实的基础。在后续文章中,我们将深入探讨GC的Mark-Sweep过程、增量GC的工作原理等