【内存分配与管理】Unity GC
在上一篇文章中,我们深入剖析了Unity托管内存的分配机制,从Boehm GC的ok_freelist与GC_hblkfreelist两级结构,到小对象与大对象的差异化分配策略,再到hblk与hblkhdr分离设计的精妙之处。我们看到了Unity如何在C++引擎层搭建起一套高效的内存分配基础设施,为C#层的对象创建提供支撑。
然而,分配只是内存管理的一半,另一半,也是我们更为关切的痛点——垃圾回收。当托管堆上的对象不再被引用时,它们占据的内存需要被回收以供后续分配使用。Unity采用的Boehm GC是一个基于Mark-Sweep的保守式GC,它的工作原理与传统GC有着显著的不同:它无法精确区分指针与非指针数据,无法对内存进行整理压缩,也无法像.NET的GC那样实现分代回收。这些特性决定了Unity GC的性能特征和局限性。
本文将从GC的触发条件入手,深入剖析Mark阶段与Reclaim阶段的完整流程,包括根节点扫描、地址到header的映射机制、标记位的管理与回收策略。通过理解这些底层原理,我们将能更好地把握Unity内存管理的本质,为后续的优化实践打下坚实基础。
托管内存管理机制
对于托管内存,其依赖于Unity的Boehm GC管理。Boehm GC是一个基于mark-sweep的保守式的GC,在Unity 2019以后,引入了增量模式以降低卡顿,其会将标记阶段均分到N帧,每帧只执行3ms,以避免单次长时间中断程序运行。
【实现GC的必要准备?】在对象被分配创建时,Unity的内存分配器会按照GC的需要组织内存布局,比如维护标记位和块信息等。
几个注意点:
.NET的GC和Unity的Boehm GC不是一个东西,Boehm GC的功能和复杂度弱于.NET的GC,跨平台性更强
无论是Mono还是IL2CPP,使用的都是Boehm GC
【保守式GC,精确式GC?】
保守式GC指的是,GC 在扫描栈或寄存器时,无法准确判断某个值是否是对象引用,只能”猜测”——如果某个字(word)的值恰好等于堆中某个对象的起始地址,就保守地把它当成引用;精确式GC指的是,GC 确切知道栈/寄存器中每个槽位的类型:是对象引用还是基本类型。
保守式GC和精准式GC相比,其缺点在哪?
一是无法对内存做整理和压缩,即把对象移动到别的地址上来整理内存,压缩碎片,其内存碎片问题严重,缓存局部性较差。
关于内存碎片问题严重:由于无法整理压缩,所以在小对象,比如大量的临时小对象(向量、UI时间、GameObject对象等),频繁地分配与回收场景下,会导致大量的外部碎片——由于内存不连续,回收后形成“空洞”,导致无法分配连续的大块内存。 【Boehm GC是如何处理内存碎片的?】Boehm GC无法从根本上消除外部碎片,只能通过一些方法缓解:
通过空闲链表ok_freelist来管理小内存块,并且这些小内存块来自于一整块完整的大内存块,尽可能的避免频繁分配销毁小对象导致过多外部碎片
在回收hblk时,会检查连续内存前后的hblk是否空闲,如果空闲会进行合并再回收到GC_hblkfreelist中
关于缓存局部性较差:整理压缩后存活对象都集中在一片连续的内存区域上,使得逻辑上相互引用的对象在物理上更加接近,提高了缓存局部性。 这使得在后续的Mark阶段中,对对象节点,即hblk进行扫描标记时的缓存命中率提高,从大量分散下的pointer chasing转变为了更接近于顺序访问
【为什么保守GC做不到整理压缩?】之所以无法做到这一点,是因为如果要做整理压缩,就必须知道指向对象的指针在哪,否则在进行整理时,无法对原先指针的指向进行更新,其依然指向旧地址
在精准GC下,编译器明确地知道内存中哪些数据是指针,绝对不会把一个整数或是其他内容解释为地址,所以可以直接枚举所有的引用,并安全地移动对象。而保守式GC缺乏精确的指针信息,只能按照数值范围、内存块状态来”猜测“,这个值是不是一个内存地址,无法精准地判断。为了避免出现整理时,漏更新指针或是误判指针的问题,所以干脆完全不整理,对象一旦分配,其地址完全固定,GC只是做标记与回收
二是存在“内存泄露”,如果一个整数值、字符串数据恰好等于一个已死亡对象的地址,那么GC会认为该值引用了该死亡对象,从而错误的认为其是可达的,该对象无法被回收。 为了避免该问题,Unity提出来几个策略:
尽量避免GC。了解自动内存管理 - Unity 手册Unity官方强调要内存重用,而不是一味地依赖于GC。常见的做法比如使用对象池、避免频繁new、重用List、Array等
尽量避免”看起来像指针的数据“、控制堆布局等。Unity在引擎层会避免看起来像指针的数据,并尽可能地控制heap区间,从而降低随机值命中堆地址的概率
将重要大块资源完全由手动管理。对于纹理、音频、动画等核心资源对象,需要用户显示地管理,只有脚本层的小对象才由Boehm GC管理
为什么Unity选择了Boehm GC?
在纯托管语言下,每个变量的类型信息、对象布局完全可以通过运行时系统得知,所以可以做到精确GC,但是在Unity引擎核心是C++,其根本不会存储这些信息。如果想要实现精确GC,那么需要给每个栈帧提供metadata,记录类型信息,但这在C++引擎下几乎不可能实现,更别提外部插件了。所以,Unity只能选择Boehm GC,只要一个值满足一系列的判断要求,就认定其为一个对象指针,其大大简化了GC的实现以及脚本层和引擎内部的交互,无需对C++引擎进行大规模改造
RAII与GC
GC下的资源对象管理和C++下的资源对象管理:
对象可以理解为“物理内存+生命周期”,这一点无论是在C++下,还是在Unity下都是共通的。二者的区别在于,谁来负责内存的管理,谁来负责生命周期的管理?
关于内存的管理,二者都是通过底层的内存分配器来分配内存。比如C++下默认的operator new使用malloc来分配内存,operator delete使用free来释放内存,而Unity同样有相应的底层分配器来进行管理,后续会看到这一点
对于生命周期的管理是二者的主要差异。C++中,通过将资源的生命周期与对象的生命周期相绑定来进行管理,即RAII。
而在Unity的托管内存模型下,内存资源的生命周期不再通过”对象的生命周期“来管理,而是通过“可达性分析”来决定,生命周期从”对象自身属性“转变为了“引用图属性”
进一步的,为什么发展出了基于“可达性”分析的托管内存,其相较于基于“作用域”管理方式有什么优点吗?
基于对象的生命周期来管理,其隐含了一个前提——对象的生命周期是相互嵌套的,但如果一个资源对象想要被共享呢,那资源对象应该由谁来释放呢? 从数据结构的角度来看,对象间的关系从树结构转变为了图结构,这该怎么解决?
C++的”补救方案“是shared_ptr + weak_ptr,前者通过”引用计数“让一个资源对象被共享,后者通过”弱引用“解决”循环引用“的问题,其在一定程度上缓解了问题,但没有彻底的解决,在复杂场景下依然难以对资源对象进行管理。此外,在多线程环境下,其需要需要额外的原子操作,以及可能出现递归式地资源释放,进而导致卡顿。但是,其没法解决“动态环”的问题,只能解决“静态环”
而在现代GC下,不再通过作用域来约束,而是基于“可达性”来分析,其也不再问一个资源被谁所有,而是问一个对象能不能从root访问到。 这种做法降低了资源管理的复杂度,解决了循环引用的问题,同时可以通过一系列的优化手段,比如分代与增量来优化,避免突然卡顿
那RAII相比于GC,其对于资源管理有什么优势吗?
资源释放的可控性。RAII是基于栈机制+作用域来管理资源的,可以明确地知道资源什么时候释放,相比之下,我们无法完全控制GC的时机,有可能导致卡顿问题
运行时开销。RAII成本较低,比如对于unique_ptr来说,几乎是零额外抽象成本;而GC需要Stop-The-World+递归扫描,运行时开销较大
资源类型的支持。资源实际上包括很多种——内存、文件、锁、网络连接等等,GC仅可以对向内存资源进行管理,而RAII的思路则适用于所有类型的资源管理。比如C#下,就需要通过using来实现类似于RAII的效果,以管理其他类型的资源。
垃圾回收
在展开GC前,首先明确何时触发垃圾回收?
在Boehm GC尝试从GC_hblkfreelist中获取hblk失败时,则会尝试进行垃圾回收或扩展堆内存,具体采用哪种方式的判断方式:
/* Have we allocated enough to amortize a collection? */
GC_INNER GC_bool GC_should_collect(void)
{
...
return(GC_adj_bytes_allocd() >= last_min_bytes_allocd
|| GC_heapsize >= GC_collect_at_heapsize);
}
两个条件:
一是“自从上次GC后已经分配的新内存,是否超过了一个阈值”,其中GC_adj_bytes_allocd代表了累计分配的字节数,其会为不同内存区域赋予不同的权重,逻辑是“如果已经给你分配了足够多的内存,那么就不会再分配新内存了,而应该回收一次;如果没有分配足够多的内存,其选择扩展堆”;
二是“当前堆的总大小,是否超过了一个阈值”,逻辑是“哪怕你分配速度不快,但是堆已经过大了,则应该回收一次,而不是继续扩充堆,以防止碎片问题严重”
这实际上是在尽可能地保证:在垃圾过多而不是堆内存少时进行GC,在堆内存少时扩充堆
垃圾回收主要分为两个阶段:
Mark标记阶段。首先重置内存节点的标记位(内存结点即hblk中的一个内存块对象),然后从内存的根节点开始遍历扫描内存空间,将托管堆上被引用的内存节点标记为“引用”
Reclaim回收阶段。遍历托管堆上的所有内存节点,然后将未标记为“引用”的内存节点回收
GC_INNER GC_bool GC_try_to_collect_inner(GC_stop_func stop_func) { ... //控制停止 if (GC_dont_gc || (*stop_func)()) return FALSE; //抛出事件 if (GC_on_collection_event) GC_on_collection_event(GC_EVENT_START); ... //清空标记位 GC_clear_marks(); ... //开始追踪内存节点,标记“引用”标记位 if (!GC_stopped_mark(stop_func)) { ... } //结束标记,开始回收没有被引用的内存节点 GC_finish_collection(); ... //抛出事件 if (GC_on_collection_event) GC_on_collection_event(GC_EVENT_END); }
Mark阶段
GC是如何组织这些hblkhdr和hblk的,以支持在Mark阶段快速查找对应的hblkhdr?换句话说,Unity是怎么管理的托管内存? 依赖于两个结构,一个是_top_index二级索引,另一个是一维双向侵入式链表
_top_index全局数组:为了实现地址到header的快速映射,以快速得到hblkhdr的信息,所以GC使用了二级索引结构,原理类似于虚拟内存物理内存映射的二级页表,_top_index则作为这套映射体系中的一级目录,而_bottom_index中的index[]则是二级目录,二者在物理上都是连续的数组,查找效率较高。
GC_arrays └── _top_index[TOP_SZ] // 一级索引(稀疏) ↓ bottom_index // 二级索引(按块) ├── index[BOTTOM_SZ] // 存 hdr* ├── key // 对应地址高位 ├── asc/desc_link // 排序链 即侵入式链表 └── hash_link // 哈希链(可选)具体来说,_top_index是一个稀疏数组(即不是所有的_top_index[i]都有值,只有_top_index[i]映射的地址区间内的地址被使用过,才会分配bottom_index),专门负责映射管理一大段地址空间,比如_top_index[42]代表从0x42000-0x42FFFF;而在这个范围内,bottom_index内的hdr指针数组index[]具体存放了hblkhdr信息,会一步对地址进行范围上的细分
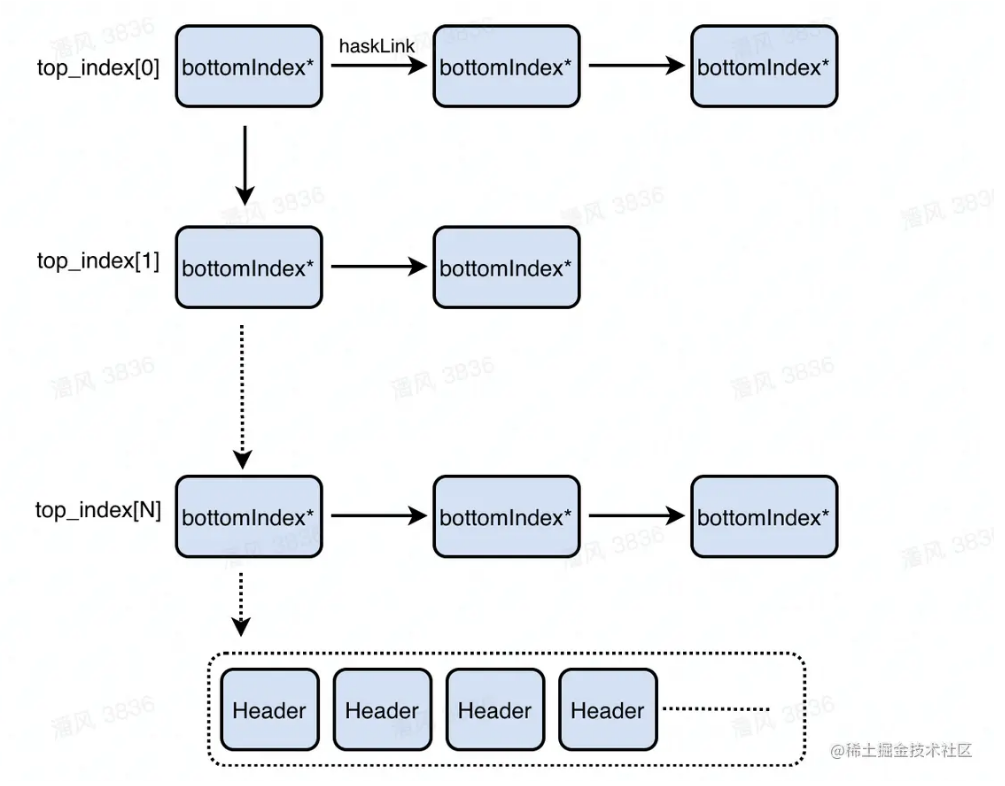
通过内存节点的地址p所应到hblkhdr的流程:通过高42位+hash算法来索引_top_index,得到对应的bottom_index;再通过12-22位置索引bottom_index中的hdr指针数组,得到hblkhdr;最后通过低12位索引到该内存节点是hblk中的第几个对象

辅助链表:Unity还维护了一个一维的侵入式双向链表来辅助管理所有的hblkhdr数据,其将_top_index二级结构“摊平展开”,将链表节点内嵌在bottom_index中实现。其是一个有序链表,按照地址的高42位来排序。

通过遍历此链表,就可以得到所有的hblkhdr以及相应的hblk地址,从而进一步遍历hblk中的内存节点
标志位重置
在正式开始扫描前,需要通过GC_clear_marks方法将所有内存节点的标记位重置,其会遍历上述提到的一维双向侵入式链表,将所有的hblkhdr中的关于内存节点的标记位都清零来重置
为什么在正式Mark前,需要先进行重置?
为了防止脏缓存影响,如果一个内存节点在第一轮GC中被引用,标记位了1,但是随着程序运行已经没有被引用了,结果在第二轮GC中其标记位依然为1,则GC会误以为其还被引用,从而永远不会被回收。
所以,在每一轮GC开始时,都先需要清除所有的mark,再从roots开始重新标记。而之所以不实时维护引用关系,主要是其成本过高,比如反向依赖追踪、写屏障管理等
线程暂停
在标记重置完成后,会将所有正在运行的线程暂停,形成一个全局一直的“内存快照”。具体来说,会暂停正在运行用户代码的线程,因为其可能会修改内存,导致引用关系发生变化,但是向当前的GC线程、阻塞线程等,则不会暂停。
【具体如何暂停线程?】
GC线程通过信号机制,给所有的目标线程发送signal,随后其他线程被被内核打断,进入GC自定义的signal handler,并在其中记录下寄存器中的状态,让线程卡在handler中不再返回
【为什么首先需要线程暂停?】
而之所以需要暂停线程,是为了正确获取到roots。roots包括静态变量、寄存器变量、每个线程的线程栈中的变量以及GC Handle。其中,静态变量和GC Handle属于uncollectable对象
GCHandle一般用于C++端对象引用C#对象,防止C#对象被回收
如果不暂停线程,那么对于线程栈来说,此时的线程栈依然在发生变化,可能漏掉引用或错误回收;此外,有的指针存储在寄存器中,还没来得及压入栈中进行写入,就很可能把对象当作垃圾回收。所以,需要将线程暂停,等完成标记后再重新恢复
【什么时候恢复?】
在下一阶段的扫描完成后,会相应的给被暂停的线程发送一个恢复信号
内存扫描
GC_INNER GC_bool GC_mark_some(ptr_t cold_gc_frame)
{
switch(GC_mark_state) {
case MS_NONE:
break;
case MS_PUSH_UNCOLLECTABLE: {
...
//
GC_push_roots(FALSE, cold_gc_frame);
GC_objects_are_marked = TRUE;
if (GC_mark_state != MS_INVALID) {
GC_mark_state = MS_ROOTS_PUSHED;
}
}
case MS_ROOTS_PUSHED: {
...
MARK_FROM_MARK_STACK();
break;
}
...
case MS_INVALID: {
...
}
break;
}
【大致流程】
内存扫描通过GC_mark_some来完成,整体流程分为四个状态,算法根据不同的状态进行相应的处理:(以下描述中,根节点内存指的是“根节点所在的内存区域”,即栈内存、寄存器保存区和全局数据段;托管堆内存节点指的是,从hblk中等分出的一个个小内存块,其存储在托管堆上并代表着一个个对象所占用的内存)
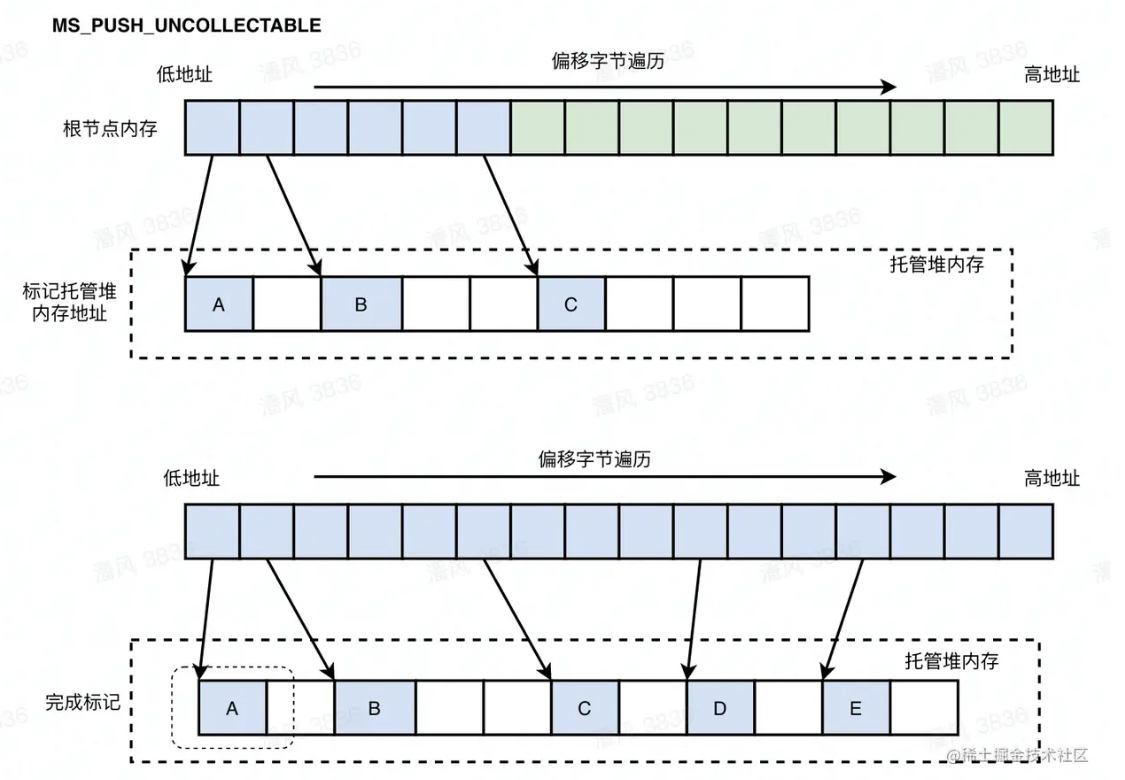
MS_INVALID:说明内存空间未开始进行扫描标记,将状态切换到MS_PUSH_UNCOLLECTABLE图中绿色方块表示未开始扫描的根节点内存,按照固定的扫描步长进行划分,64位下一般为8字节

MS_PUSH_UNCOLLECTABLE: 将GC内部维护的uncollectable对象直接加入到mark stack中,同时通过GC_push_roots()来扫描栈、寄存器和全局变量,对其中疑似指针进行验证,如果认定其是一个指针,则将对应的内存结点打上标记,并将其加入到mark stack(mark stack是用数组实现的显式 DFS 工作栈)中。 完成后,将状态切换到MS_ROOTS_PUSHED如图,从根节点内存的起始地址开始,按照固定步长扫描,蓝色代表已经被扫描的内存空间,且被引用的“托管堆内存节点”会被标记为蓝色,为指向的全部标记为白色(会被回收)
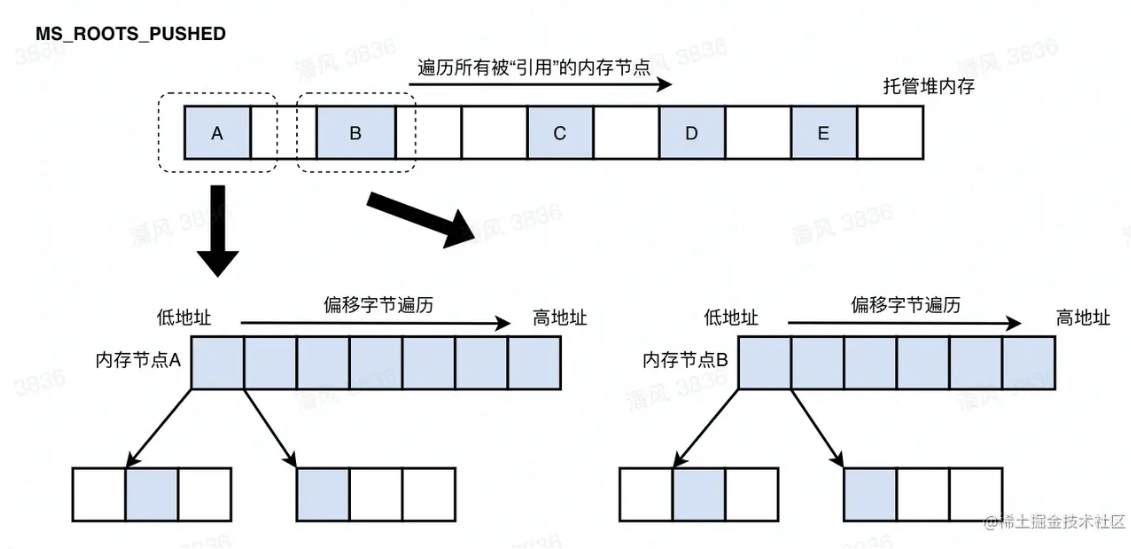
MS_ROOTS_PUSHED:继续扫描之前被引用的“托管堆内存节点”,对mark stack进行“pop->扫描验证->push”的方式,递归式地为所有被引用的内存节点打上标记,随后切换到MS_NONE状态。所有未被标记的内存节点会被GC回收
MS_NONE:表示扫描全部结束
MS_PUSH_UNCOLLECTABLE阶段的具体逻辑是什么?具体怎么扫描的?
核心扫描逻辑GC_push_all_eager:
GC_API void GC_CALL GC_push_all_eager(void *bottom, void *top) {
...
lim = t - 1
for (p = b; (word)p <= (word)lim;
p = (word *)(((ptr_t)p) + ALIGNMENT)) {
REGISTER word q = *p;
GC_PUSH_ONE_STACK(q, p);
}
}
扫描范围即栈内存区、寄存器保存区和全局数据区,通过bottom和top将该内存区域标识出来,并按照word步长从bottom开始进行扫描,直到top结束。可以理解为将整个连续的内存区域按照word大小等分为若干个“内存块”,将存储的数据交给GC_PUSH_ONE_STACK进行检查,看其是否“像一个指针”
for (p = bottom; p <= top; p += 8) {
q = *p; //q即
}
核心检查逻辑GC_PUSH_ONE_STACK:
GC_INNER void GC_mark_and_push_stack(ptr_t p, ptr_t source) {
hdr * hhdr;
ptr_t r = p;
PREFETCH(p);
GET_HDR(p, hhdr);
//能取到header信息
if (NULL == hhdr|| (r = (ptr_t)GC_base(p)) == NULL|| (hhdr = HDR(r)) == NULL)) {
return;
}
//判断空闲状态
if (HBLK_IS_FREE(hhdr) {
return;
}
...
//标记并加入临时数组
PUSH_CONTENTS_HDR(r, GC_mark_stack_top, GC_mark_stack_limit,
source, hhdr, FALSE);
}
GC_PUSH_ONE_STACK接收到”内存块“中的值,分为多步进行检查判断,只有通过了检查,才会将该值作为一个内存地址并将对应的hblk进行标记,防止被回收。 对于绝大多数的值来说,其根本不是一个内存地址,需要被过滤:
首先判断”该值代表的内存地址“是否在托管堆范围内。 托管堆的范围会在GC_hblklist中无可分配内存块时,调用内存分配接口时更新。这一步可以过滤掉绝大多数的垃圾值,即不代表内存地址的值
NULL == hhdr 判断能否通过该内存地址获取到hblkhdr信息。 具体来说,以内存地址索引全局数组_top_index,类似于虚拟地址和物理地址映射的流程,尝试获取到header信息。
p 的高位 → 查 _top_index → 得到 bottom_index p 的中间位 → 在 bottom_index 里找 slot → 得到 hblk 对应的 header这一步是因为第一步的范围限制只是一个粗略区间,托管堆并不是完全连续的,中间可能存在未分配区域。 如果值代表的内存地址命中了这些空洞区域,同样会将其排除在外,不认为其是一个被引用的对象,不会被打上标记
[heap chunk A] [heap chunk B] [heap chunk C] ↑ ↑ ↑ 有 header 有 header 有 headerGC_base(p) 用于根据给定的地址,找出其属于哪个对象,并返回该对象的地址。 这一步主要通过header提供的信息来完成,比如hb_size。如果可以对应到一个对象的起始地址,则不会return,会进入后续流程比如,下面的q存储了对象内部的地址,其不应该被回收。总结一下,这一步检测的意义在于,即使程序中只保存了对象内部地址,该对象依然可以被正确标记为存活
struct Obj { int a; int b; int c; }; Obj* o = new Obj(); // 栈里可能出现: q = &o->b;HBLK_IS_FREE判断当前对应的hblk是否是空闲的,如果hblk为空闲状态,则不会被标记,需要被GC回收。 这一步通过hblkhdr中的hb_flags信息来判断,该信息一般会在两处被更改——
GC扫描后发现该hblk中没有一个存活对象时,调用GC_freehblk将hb_flags变为FREE空闲(hhdr->hb_flags |= FREE_BLK;),在hblk从系统底层分配出来时,同样也会被设置为FREE空闲
将hblk中的内存结点提供给上层使用时,将hb_flags变为USED被使用
标记逻辑PUSH_CONTENTS_HDR
# define PUSH_CONTENTS_HDR(current, mark_stack_top, mark_stack_limit, source, hhdr, do_offset_check) { \ //计算内存节点位于的hblk内存块地址的偏移值 size_t displ = HBLKDISPL(current); \ size_t gran_displ = BYTES_TO_GRANULES(displ); \ ... //将header中对应的标记位设置为1,表示这个节点被“引用” SET_MARK_BIT_EXIT_IF_SET(hhdr, gran_displ); \ ... //增加引用个数hb_n_marks INCR_MARKS(hhdr); \ ... //将内存节点存入临时数组中 PUSH_OBJ(base, hhdr, mark_stack_top, mark_stack_limit); \ ... }**至此,我们确定了该值是一个内存地址,所以需要计算该内存地址引用的是hblk中的哪一个内存结点,以在对应的hblkhdr中做标记。**例如hblk内存块的地址是0x122c86900,hb_sz=16(节点大小16字节),内存节点A的地址是0x122c86920,则偏移32字节,Header->hb_marks[1]存储A的“引用”状态标记位的值0或1。如果内存地址对应是节点A的地址,则先调用调用SET_MARK_BIT_EXIT_IF_SET,将对应的hb_marks[1]和hb_marks[2]标记为1,代表该内存节点正在被引用;再调用INCR_MARKS方法将hb_n_marks加一,表示这个hblk内存块中被“引用”的节点总数加一。如图所示。蓝色表示被“引用”的2个内存节点,
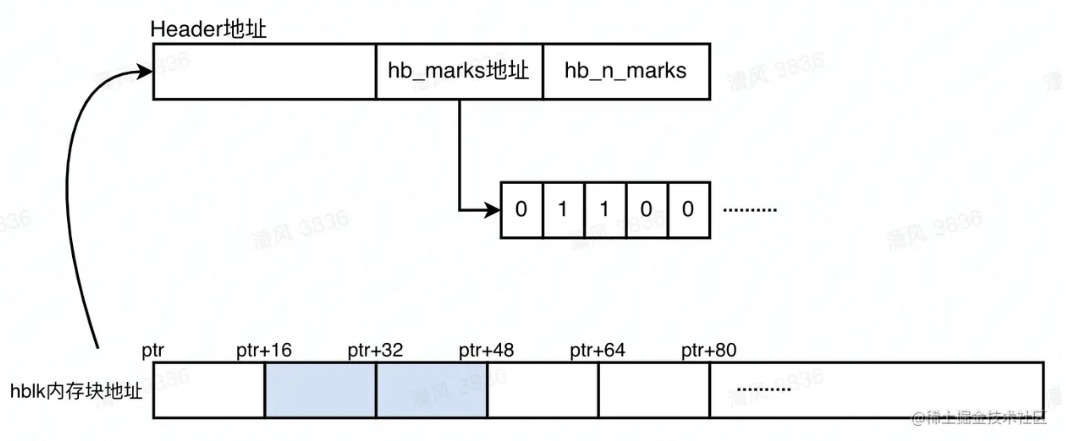
最后,再调用PUSH_OBJ,将“引用”的内存结点的地址加入到一个临时数组mark stack中,为接下来针对“托管堆内存节点”递归扫描做准备
Reclaim阶段
STATIC void GC_finish_collection(void)
{
...
//检测内存泄漏逻辑
if (GC_find_leak) {
for (kind = 0; kind < GC_n_kinds; kind++) {
for (size = 1; size <= MAXOBJGRANULES; size++) {
q = (ptr_t)GC_obj_kinds[kind].ok_freelist[size];
if (q != NULL)
GC_set_fl_marks(q);
}
}
//不实际回收
GC_start_reclaim(TRUE);
}
...
//清空ok_freelist链表
for (kind = 0; kind < GC_n_kinds; kind++) {
for (size = 1; size <= MAXOBJGRANULES; size++) {
q = (ptr_t)GC_obj_kinds[kind].ok_freelist[size];
if (q != NULL)
GC_clear_fl_marks(q);
}
}
//开始回收
GC_start_reclaim(FALSE);
...
}
主要的GC逻辑集中于GC_start_reclaim:
GC_INNER void GC_start_reclaim(GC_bool report_if_found)
{
for (kind = 0; kind < GC_n_kinds; kind++) {
struct hblk ** rlist = GC_obj_kinds[kind].ok_reclaim_list;
...
//清空ok_freelist和ok_reclaim_list
void **lim = &(GC_obj_kinds[kind].ok_freelist[MAXOBJGRANULES+1]);
for (fop = GC_obj_kinds[kind].ok_freelist; (word)fop < (word)lim; (*(word **)&fop)++) {
...
GC_clear_fl_links(fop);
}
...
BZERO(rlist, (MAXOBJGRANULES + 1) * sizeof(void *));
}
...
//加入ok_reclaim_list链表
GC_apply_to_all_blocks(GC_reclaim_block, (word)report_if_found);
...
//回收内存
GC_reclaim_all((GC_stop_func)0, FALSE);
...
}
- 首先通过GC_clear_fl_links将 ok_freelist 中的节点全部清空,为后续新的free对象加入到ok_freelist中腾出空间。同时,将ok_reclaim_list清空,为佳能free对象回收到其中做好准备
- 随后,通过GC_apply_to_all_blocks遍历之前提到的bottomIndex一维链表,其中存储了指向hblkhdr的指针。其针对每个hblk,调用GC_reclaim_block来预处理要回收的内存块——大对象直接回收,小对象则暂时加入到ok_reclaim_list中,并通过GC_reclaim_all实际回收,将其加入到ok_freelist下
- 最后,会遍历GC_hblkfreelist以尝试将hblk归还给操作系统。是否归还取决于该hblk有多久没有被使用过了,如果经过了6次GC都没有被分配出去过,那么Boehm GC会将该hblk对应的物理内存归还给操作系统,但其虚拟地址会被保留,日后再次申请这块内存时,hblk地址不变
GC_reclaim_block:
STATIC void GC_reclaim_block(struct hblk *hbp, word report_if_found)
{
hdr * hhdr = HDR(hbp);
word sz = hhdr -> hb_sz; /* size of objects in current block */
struct obj_kind * ok = &GC_obj_kinds[hhdr -> hb_obj_kind];
if( sz > MAXOBJBYTES ) { /* 1 big object */
if( !mark_bit_from_hdr(hhdr, 0) ) {
...
//直接释放hbp到GC_hblkfreelist链表中
GC_freehblk(hbp);
}
else {
...
GC_bool empty = GC_block_empty(hhdr);
if (empty) {
GC_freehblk(hbp);
} else if (!GC_block_nearly_full(hhdr)) {
struct hblk **rlh = ok -> ok_reclaim_list;
if (rlh != NULL) {
rlh += BYTES_TO_GRANULES(sz);
hhdr -> hb_next = *rlh;
*rlh = hbp;
}
}
}
...
}
对于大对象:大对象较为特殊,一个内存节点直接由1-N个hblk内存块构成,不像小对象,一个hblk会等分为多个小内存节点供上层使用。所以,如果通过hblkhdr检查出该hblk未被引用,则直接通过GC_freehblk方法,将其加入到GC_hblkfreelist中,同时把内存中的数据清空,以供下次大内存分配使用
需要注意,GC_freehblk会尝试进行内存块的合并:如果要归还的hblk前后的hblk是空闲的,则会进行合并,再归还给GC_hblkfreelist
对于小对象需要分类讨论:
如果整个hblk为empty,即hblk中没有任何一个节点被引用,则直接通过GC_freehblk将整个hblk归还给GC_hblkfreelist,并清空数据
通过GC_block_nearly_full方法判断,当前hblk中是否大多数节点被引用(如果当前heap block中被标记的object数量 > (7/8) * heap block能容纳的总object数量,则认定为大多数被引用)。如果不是,即大多数内存结点都没有被引用,则将该hblk加入到ok_reclaim_list中,其在大小上的结构和ok_freelist一致
如果当前hblk中大多数内存节点被引用,则不加入到ok_reclaim_list中,什么也不做
GC_reclaim_all:真正将hblk内存块回收。
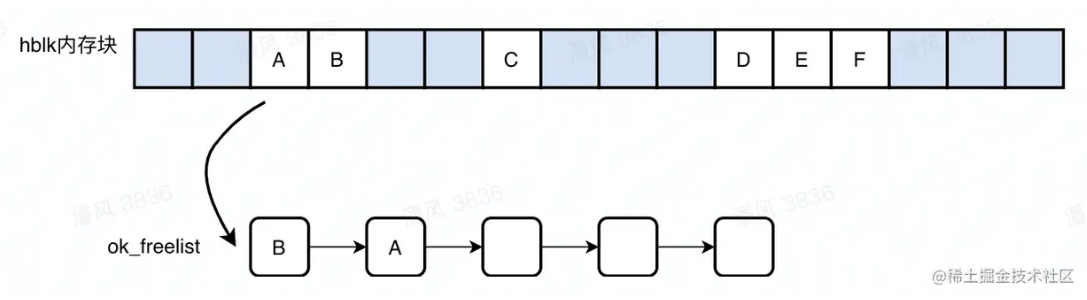
遍历所有的ok_reclaim_list链表,取出hblk内存块遍历hblk内存中的每个内存节点,如果mark_bit_from_hdr为1,表示被标记“引用”,不需要回收,否则将其加入list中,即ok_freelist链表。如图所示:
至此,垃圾回收全部完成。梳理一下非增量BoehmGC的整体流程:
清空所有标记位
暂停用户线程(stop-the-word)
【Mark】从root触发做可达性分析。将uncollectable对象加入mark stack,并扫描根节点内存,判定值是否是指针,如果是则加入mark stack并打上标记
【Mark】对mark stack中的托管堆对象进行递归式地扫描并标记
【Sweep】恢复线程执行,遍历所有的堆对象(bottomIndex全局双向链表),对于小对象,如果其所在的hblk整体空闲,则回收到GC_hblkfreelist中,如果hblk大部分空闲,则回收到ok_freelist中,否则不做处理;对于大对象则直接回收到GC_hblkfreelist。如果某个GC_hblkfreelist中的内存块连续六次GC都未被使用,则物理内存被回收
总结
本文详细拆解了Unity GC的完整工作流程,从触发条件到Mark阶段的根节点扫描与递归标记,再到Reclaim阶段的分级回收策略。我们可以看到,Boehm GC作为一款保守式GC,虽然在功能复杂度上不及.NET的精确式GC,但通过精心设计的数据结构与分配策略,在跨平台兼容性与实现简洁性之间找到了平衡。
在下一篇文章中,我们将进一步探讨增量式GC的工作原理——Unity如何将原本一次性的标记阶段分摊到多帧执行,从而将长时间的STW停顿转化为多次短暂的微停顿,大幅改善游戏的帧率稳定性。